
AWS NEPTUNE 적용기 (5) - Node.js에서 Neptune 사용하기
이전 포스트 AWS NEPTUNE 적용기 (4) - Python에서 Neptune 사용하기에서는 Python을 사용해 넵튠 데이터베이스에 접근해보았다면, 이번 포스트에서는 Node.js를 사용해 연결하는 과정을 담아보려 한다. 프로젝트를 진행하면서 Python을 사용했던 것은 데이터를 처리하기 위해서였는데, 한편 Node.js는 Web API를 구축하기 위해 사용했다. 사용자가 직접 데이터를 추가하는 기능은 없기에 이 API 서버에서는 데이터를 조회해서 뿌려주는 작업이 주로 이루어진다. 그래서 Neptune과의 연결에서는 그래프를 순회하도록 하는 것이 주된 작업이었다.
그래프를 순회하기 이전에, Python에서 Neptune DB에 연결하고 쿼리를 실행하기 위해 사전 환경 설정이 필요했듯, Node.js에서도 먼저 환경 구축이 필요하다.
Node.js 사전 설정
참조
Node.js를 사용하여 Neptune DB 인스턴스에 엑세스하기
1. 패키지 설치
본 프로젝트는 node v12.18.2 환경에서 진행했다. 먼저, npm을 사용해 넵튠에 쿼리를 실행할 수 있도록 하는 gremlin 관련 패키지를 설치한다.
npm install gremlin
2. Neptune 연결 사전 설정
Neptune에 연결하기 위해서 아래와 같이 Neptune DB 인스턴스의 주소를 기입해야한다.
'wss://your-neputne-endpoint:8182/gremlin'
나는 wss, endpoint, 8182 모두 변수로 지정하여 사용했고, 이를 위해 dotenv 라이브러리를 설치하여 사용했다. 각 변수에 대한 설명은 이전 포스트의 Python으로 연결 시 사전 설정를 참고하면 된다. 이전 포스트에서 사전 설정했던 방식과 유사하게 진행했으며, 마찬가지로 .env 파일을 생성해 파일 안에 변수를 정의했다. 정의한 변수를 config/index.js 파일에 넣어 다른 파일에서도 읽을 수 있도록 했다.
// config/index.js
const env = require('dotenv')
const envConfig = env.config()
if (envConfig.error) {
throw new Error('Cannot find .env file')
}
module.exports = {
// Neptune Database env
neptuneProtocol: process.env.NEPTUNE_PROTOCOL,
neptuneHost: process.env.NEPTUNE_HOST,
neptunePort: process.env.NEPTUNE_PORT,
}
클래스 생성해 연결하기
먼저, Neptune DB에 연결하기 위한 loader 파일을 생성했다. 해당 파일에서 연결을 위한 작업을 실행하고, 순회에 필요한 모듈을 다른 파일에서 사용할 수 있도록 export했다. 이러한 작업을 수행하기 위해서는 사전에 설치한 패키지로부터 필요한 모듈을 가져와야한다.
1. 모듈 import
AWS 공식 문서에서 제공하는 코드를 참조하여 모듈을 import했다.
// loader/graphdb.js
const gremlin = require('gremlin')
const DriverRemoteConnection = gremlin.driver.DriverRemoteConnection
const Graph = gremlin.structure.Graph
const graph = new Graph()
2. Singleton 클래스 생성
나는 AWS 공식 문서에서 제공하는 코드를 조금 변형하여 사용했는데, AWS 공식 문서의 코드는 아래와 같다.
const gremlin = require('gremlin');
const DriverRemoteConnection = gremlin.driver.DriverRemoteConnection;
const Graph = gremlin.structure.Graph;
dc = new DriverRemoteConnection('wss://your-neptune-endpoint:8182/gremlin',{});
const graph = new Graph();
const g = graph.traversal().withRemote(dc);
Neptune 데이터베이스에 연결할 때마다 Neptune DB와의 연결이 이루어지지 않도록 연결 객체가 한 번만 생성되게끔 Singleton Pattern으로 클래스를 정의했다.
class GraphdbConnectionManager {
construnctor(endpoint) {
if (!GraphdbConnectionManager.instance) {
this._remoteConnection = new DriverRemoteConnection(endpoint, {})
GraphdbConnectionManager.instance = this
}
return GraphdbConnectionManager.instance
}
getRemoteConnection() {
return this._remoteConnection
}
}
3. Neptune DB에 연결하기
위와 같이 정의한 클래스로 connection 객체를 생성해 Neptune DB 인스턴스에 연결할 수 있도록 했다. loader/graphdb.js 전체 코드는 아래와 같다.
// loader/graphdb.js
const config = require('../config/index')
const gremlin = require('gremlin')
const DriverRemoteConnection = gremlin.driver.DriverRemoteConnection
class GraphdbConnectionManager {
construnctor(endpoint) {
if (!GraphdbConnectionManager.instance) {
this._remoteConnection = new DriverRemoteConnection(endpoint, {})
GraphdbConnectionManager.instance = this
}
return GraphdbConnectionManager.instance
}
getRemoteConnection() {
return this._remoteConnection
}
}
const endpoint = `${config.neptuneProtocol}://${config.neptuneHost}:${config.neptunePort}/gremlin`
const graphdbConnectionManager = new GraphdbConnectionManager(endpoint)
const remoteConnection = graphdbConnectionManager.getRemoteConnection()
const Graph = gremlin.structure.Graph
const graph = new Graph()
const g = graph.traversal().withRemote(remoteConnection)
module.exports = { gremlin, g }
위의 코드에서 export한 g는 이후 다른 파일에서 그래프를 순회하는데 사용할 수 있다.
그래프 순회하기
loader/graphdb.js에서 export한 모듈을 사용해 그래프를 순회하는 메소드를 생성했다.
1. 메소드 생성 및 모듈 import
순회를 위해 loader/graphdb.js에서 g 모듈을 export하기도 했지만, gremlin 모듈 또한 export했는데 이 모듈은 그래프를 순회할 때 범위를 지정하거나 순회 시 option을 줄 수 있는 역할을 한다. 따라서 메소드 내에 먼저 필요한 모듈을 import해와야 한다.
import하기 전에, 메소드를 생성할 때 async 를 붙임으로써 메소드 안에서 비동기 처리가 이루어질 수 있도록 했다. 그래프 데이터베이스에 접근하여 결과를 얻는 과정을 비동기적으로 처리하기 위해서이다.
async getRelatedVideoReviews(keywords) {
const { gremlin, g } = require('../loaders/graphdb')
const P = gremlin.process.P
const s = gremlin.process.s
const order = gremlin.process.order
const column = gremlin.process.column
}
2. 그래프 순회 코드
edge 이름 기반으로 순회하기
그래프를 순회하는 것은 AWS NEPTUNE 적용기 (1)에서도 언급했듯, 사용자가 눌러본 키워드(메뉴)를 기반으로 콘텐츠를 추천해주기 위해서이다. 추천을 위해 처음에 진행했던 순회 방식은 데이터베이스 설계 방식에 기초했다. 초기에 구축했던 그래프데이터베이스의 스키마를 기반으로 순회 방식을 고려했는데, 초기 그래프데이터베이스는 keyword, video_review, category 세 종류의 node들이 아래와 같은 관계를 맺고 있는 모습이었다.
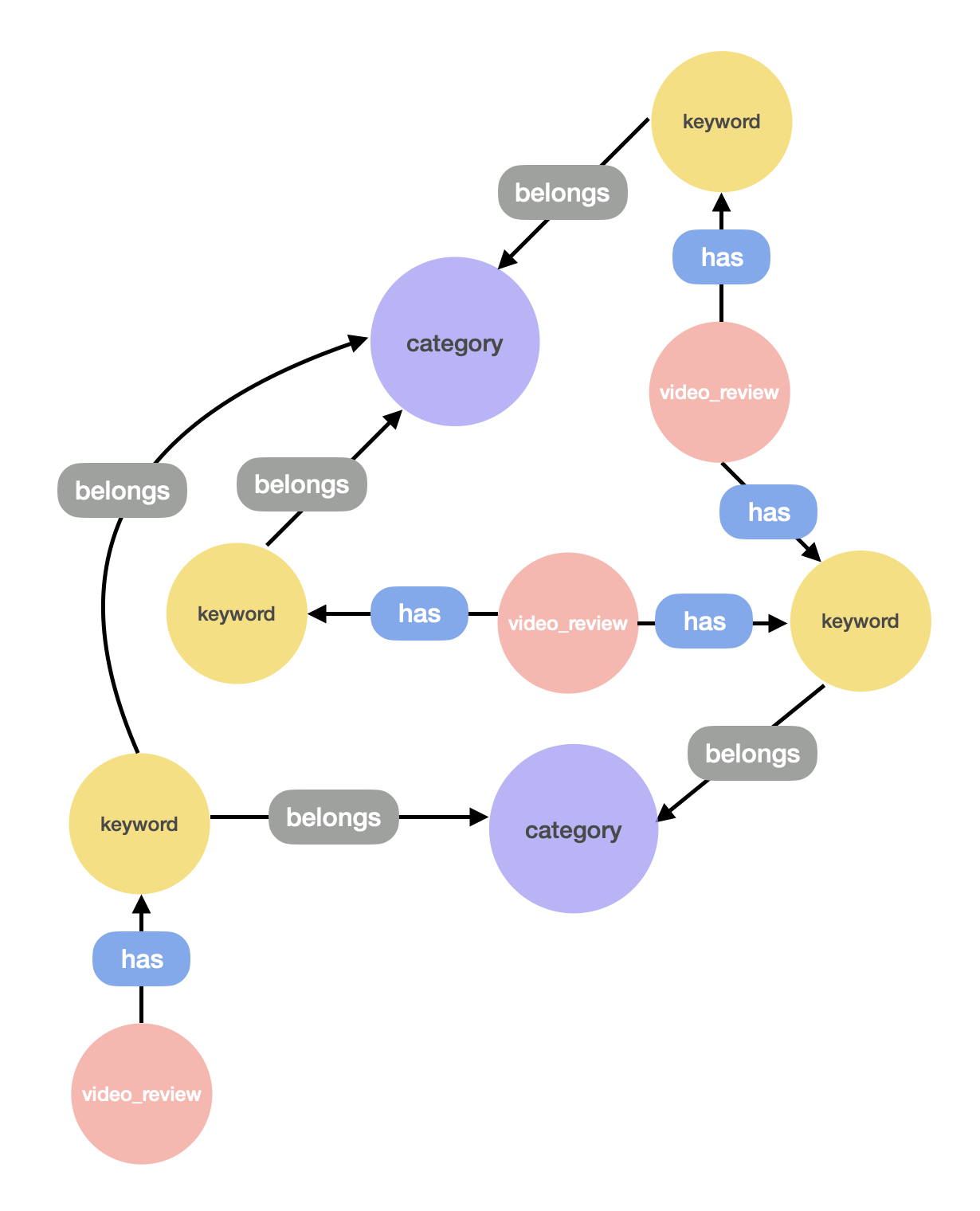
이러한 관계를 맺고 있는 데이터를 고려했을 때, 사용자가 키워드를 누르면 keyword가 속하는 category 노드들을 찾고, 각 category 노드가 갖고 있는 keyword 노드들을 찾은 후 각각의 keyword 노드들을 갖고 있는 video_review 노드들을 찾는다면 사용자가 눌러본 키워드를 기반으로 영상을 추천해줄 수 있을 것이라 판단했다. 글로 쓰려니 복잡한데, 간단히 표현하면 다음과 같다.
눌러본 keyword –belongs–> category <–belongs– keyword <–has– video_review
이 때 각각의 video_review 노드가 위와 같은 순회에 의해 몇 번 찾아지게 되는지 횟수를 센다면, 이 횟수가 높을수록 사용자가 눌러본 키워드와 관련도가 높은 영상일 것이라 생각했다. 이렇듯, 설계한 스키마를 토대로 특정 label을 가진 ‘edge’를 타고 그래프를 순회하는 방식이 첫 번째로 고안했던 방식이었다.
이러한 로직을 코드로 나타낸 것은 아래와 같다.
async getRelatedVideoReviewsUsingEdge(keywords) {
const { gremlin, g } = require('../loaders/graphdb')
const P = gremlin.process.P
const s = gremlin.process.scope
const order = gremlin.process.order
const column = gremlin.process.column
try {
const result = await g
.V()
.has('name', P.within(keywords))
.out('belongs')
.in_('belongs')
.in_('has')
.groupCount()
.order(s.local)
.by(column.values, order.desc)
.limit(s.local, 15)
.toList()
return result
} catch (e) {
if (e instanceof ReferenceError || e instanceof SyntaxError) {
throw 'Neptune syntax or reference error'
}
throw e.message
}
}
사용자가 keyword를 하나만 선택하는 것이 아니고, 여러 키워드를 눌러볼 수 있기 때문에 위 메소드의 parameter로 들어오는 ‘keywords’는 배열이다. 배열 안에 들어온 각각의 키워드마다 belongs label을 가진 edge를 타고 카테고리를 찾고, 카테고리에 in 방향으로 들어온 belongs edge를 타고 키워드를 찾고, 같은 방식으로 영상 노드를 찾아 나가는 것이다.
order().by()를 통해 count가 많은 순서대로 정렬하도록 하면 결과값으로 Map의 배열을 반환한다. keywords 매개변수로 [‘찐만두’, ‘돈가스’, ‘밀전병’]을 전달했을 때 아래와 같은 결과를 얻을 수 있었다.
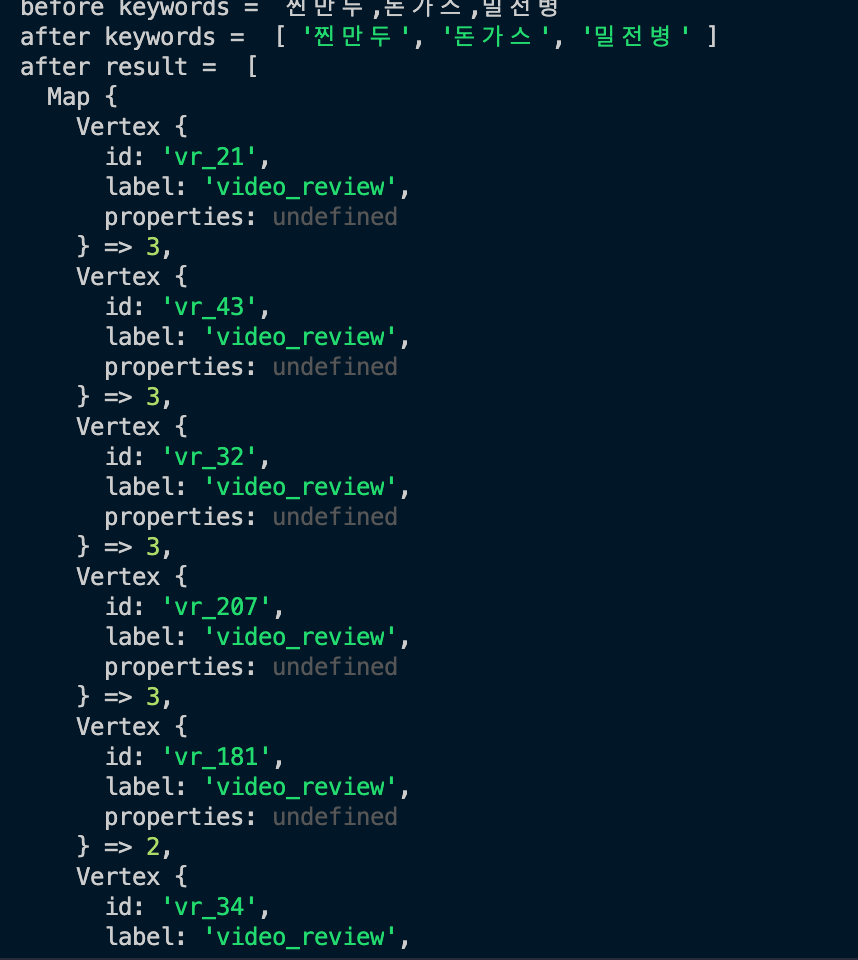 3, 2와 같은 숫자는 각 영상이 순회하면서 조회된 횟수로 위 사진은 이 숫자에 대한 내림차순으로 정렬한 결과이다.
3, 2와 같은 숫자는 각 영상이 순회하면서 조회된 횟수로 위 사진은 이 숫자에 대한 내림차순으로 정렬한 결과이다.
거리 기반으로 순회하기
위와 같이 edge의 label 이름을 기반으로 순회할 경우에는, 만약 새로운 label을 가진 노드가 추가되거나 노드/엣지의 label 이름이 변경된다면 문제가 발생할 수 있다. 새로운 label을 가진 노드가 추가될 경우, 위의 방식은 새로 추가되는 관계를 고려하지 못하게 된다. 한 두개의 새로운 관계가 추가될 경우 쿼리에 반영할 수 있겠지만, 이후 관계가 더 복잡해진다면 이 모든 관계를 다 추가하기는 어려울 것이다. 그래서 새로 고안한 방법은 거리를 기반으로 순회하도록 하는 것이다. 새로 고안한 방법을 배포 버전에 반영했는데, 이전의 방식보다 간단하며 노드/엣지가 맺고 있는 관계나 스키마를 신경쓰지 않아도 되기 때문이었다. 해당 메소드는 다음과 같다.
async getRelatedVideoReviewsUsingDistance(keywords) {
const { gremlin, g } = require('../loaders/graphdb')
const P = gremlin.process.P
const s = gremlin.process.scope
const order = gremlin.process.order
const column = gremlin.process.column
const __ = gremlin.process.statics
try {
const result = await g
.V()
.has('name', P.within(keywords))
.repeat(__.both())
.times(3)
.filter(__.label().is('video_review'))
.groupCount()
.order(s.local)
.by(column.values, order.desc)
.limit(s.local, 15)
.toList()
return result
} catch (e) {
if (e instanceof ReferenceError || e instanceof SyntaxError) {
throw 'Neptune syntax or reference error'
}
throw e.message
}
}
처음 방식과 다른 부분은 repeat().times().filter() 부분이고 나머지 부분은 동일하다. 이 메소드에서는 사용자가 선택한 키워드들을 시작점으로 하여 in/out 방향과 관련 없이 연결된 edge를 타고 순회한다. edge 하나를 사이에 둔 두 노드 간의 거리가 1이라고 할 때, 선택한 키워드를 기준으로 거리가 3 이내에 있는 노드들 중 label이 video_review인 노드들을 필터링하도록 했다. 결과값 형식은 getRelatedVideoReviewsUsingEdge() 메소드의 반환 형식과 동일하다.
마무리하며
위와 같이 순회 쿼리를 실행하는 메소드를 생성해 사용자가 눌러본 키워드를 기반으로 다음 영상을 추천해줄 수 있는 API를 개발했다. 이렇게 그래프 데이터베이스를 활용해 간단한 추천 기능을 구현해낼 수 있었다. 추천이라고 하기엔 조금 민망할만큼 비교적 간단한 로직이지만, 이 추천 로직을 구현하기 위해 그래프데이터베이스라는 개념을 접해보고 Neptune도 사용해볼 수 있었던 재밌는 경험이었다.
이번 포스트까지가 Neptune을 사용하기 위한 필수적인 단계들을 정리한 것이었다면, 다음 포스트부터는 시각화나 백업, 인스턴스 삭제 등 부가적인 것을 다뤄보고자 한다.
Leave a comment