
AWS NEPTUNE 적용기 (4) - Python에서 Neptune 사용하기
이전 포스트 AWS NEPTUNE 적용기 (3) - Gremlin 사용하기에서도 언급했듯이, 기존 그래프를 Amazon Neptune으로 마이그레이션이나 대량 로드를 통해 데이터를 삽입할 수 있다.
진행한 프로젝트에서는 Amazon RDS에 있는 관계형 데이터 중 필요한 데이터만을 추출하여 Neptune에 노드와 엣지로 삽입하는 작업을 진행했다. 프로젝트에서 데이터 크롤링이나 처리 작업은 python으로 진행했기에 그래프 데이터베이스에 삽입하는 것도 python으로 코드를 작성했다. 이번 포스트에서는 python 으로 Neptune에 연결하고 데이터를 처리했던 과정을 다뤄보고자 한다.
Python 사전 설정
참조
Python을 사용하여 Neptune DB 인스턴스에 엑세스하기
1. 패키지 설치
프로젝트는 Python 3.6 이상의 환경에서 진행했다. Python에서 Gremlin을 사용하기 위해서는 사전 패키지 설치가 필요하다.
pip install gremlinpython --user
나는 패키지 관리와 개발환경 관리를 위해 프로젝트를 위한 별도의 python 가상환경을 사용했고, 가상환경 내에 위의 패키지 설치를 진행했다.
2. Neptune 연결 사전 설정
python 어플리케이션을 Amazon Neptune에 연결하는 단계이다. 연결을 위해서는
remoteConn = DriverRemoteConnection('wss://your-neptune-endpoint:8182/gremlin','g')
가 필요한데, 나는 neptune endpoint 뿐만 아니라 wss와 8182까지 변수로 만들어 사용했다.
💡 연결 프로토콜과 포트번호
여기서wss는 Neptune 인스턴스에 연결하는 Protocol 방식이다. 웹소켓 프로토콜으로wss는 암호화된 연결 프로토콜이며ws의 경우 암호화되지 않은 연결이다. Neptune은 SSL 강제 연결 적용에서도 확인할 수 있듯 적어도 서울 리전에서는wss연결만 가능하다.8182는 Neptune 인스턴스에 연결할 수 있는 port 번호이다.
로컬에서 Neptune 인스턴스 접근을 할 수 있는 방법을 찾다가 스택오버플로우에서 다음 답변(https://stackoverflow.com/a/52622164)를 찾았다. ALB를 neptune과 같은 VPC에 설치해 프록시와 같은 역할을 하도록 했는데, 로컬 <-> alb proxy은 ws방식으로 소통하고 alb proxy <-> neptune은 wss방식으로 소통하게끔 했다. 따라서 위 DriverRemoteConnection에 들어가는 protocol에는 wss가 아닌 ws를 썼다. 엔드포인트도 Neptune 엔드포인트가 아닌 ALB endpoint를 썼다.
(로컬에서 Neptune에 접근하기 위한 방법은 차후 포스팅할 것이다!)
이 방식으로 며칠 써보다가 연결이 자주 끊기는 문제가 발생해서 alb를 없애고 다시 원상태로, 즉 다시 wss 방식으로 연결했다. 이렇듯 엔드포인트 뿐만 아니라 프로토콜 방식도 바꾸는 경우가 생겨서, 편리함을 위해 프로토콜 방식/엔드포인트/포트 넘버 모두를 변수로 만들었다.
dotenv 사용하기
pip install python-dotenv
위의 명령어를 통해 가상환경에 dotenv 패키지를 설치하고 .env 파일을 생성하여 파일 안에 변수를 정의했다.
NEPTUNE_PROTOCOL=wss
NEPTUNE_HOST=neptunedbcluster-xxxxxxxx.neptune.amazonaws.com
NEPTUNE_PORT=8182
클래스와 메소드 만들기
Neptune 데이터베이스 인스턴스에 연결하고 쿼리를 실행하기 위한 메소드들을 하나의 클래스로 묶었다. 인스턴스에 연결하고 쿼리 실행을 위해서는 필요한 모듈을 import해와야 한다.
1. 모듈 import
from gremlin_python import statics
from gremlin_python.structure.graph import Graph
from gremlin_python.process.graph_traversal import __
from gremlin_python.process.strategies import *
from gremlin_python.driver.driver_remote_connection import DriverRemoteConnection
위는 AWS 공식 문서에서 제공하는 코드이고, 나는 추가적으로 순회 시 필요한 모듈을 import했다.
from gremlin_python.process.traversal import T
2. 싱글톤(Singleton) 클래스 정의
앞서 언급했듯, Neptune 데이터베이스에 쿼리를 실행하기 위한 메소드들을 하나의 클래스로 묶었는데, 데이터베이스에 연결해야 할 때마다 너무 많은 데이터베이스 객체가 만들어질 수 있다. 이를 막기 위해 객체를 생성하기 위한 생성자가 여러번 호출되어도 실제로 하나의 객체만 생성되도록 하고 첫 생성 이후 생성자를 호출할 경우 이미 생성된 객체를 반환하는 Singleton Pattern을 따르도록 클래스를 정의했다. (singleton pattern을 따르지 않아도 된다.)
class GraphdbSingleton(type):
__instances = {}
def __call__(cls, *args, **kwargs):
if cls not in cls.__instances:
cls.__instances[cls] = super().__call__(*args, **kwargs)
return cls.__instances[cls]
Neptune 인스턴스에 접근해 쿼리를 실행하는 메소드들을 묶은 클래스는 위의 singleton class인 GraphdbSingleton을 metaclass로 지정해줌으로써 아래와 같이 정의했다.
class GraphdbController(metaclass = GraphdbSingleton):
pass
이를 통해 생성자 GraphdbController()로 객체를 생성할 때 Sigleton class의 __call__이 호출된다. __call__ 메소드 안에서 인스턴스의 존재 여부를 확인해 이미 생성된 객체가 있다면 이를 반환한다.
3. Neptune DB에 연결하기
GraphdbController 객체가 처음 생성될 때 GraphdbController에 __init__메소드가 있다면 이 메소드가 먼저 실행되는데, 나는 이 메소드에서 Neptune 인스턴스와의 연결이 이루어지도록 했다. 또한 쿼리 실행 메소드들에서 필요한 변수를 이 안에서 정의했다.
import os
from dotenv import load_dotenv
load_dotenv(verbose=True)
NEPTUNE_PROTOCOL = os.getenv('NEPTUNE_PROTOCOL')
NEPTUNE_HOST = os.getenv('NEPTUNE_HOST')
NEPTUNE_PORT = os.getenv('NEPTUNE_PORT')
class GraphdbController(metaclass = GraphdbSingleton):
def __init__(self):
self.__graph = Graph()
statics.load_statics(globals())
self.__remoteConn = DriverRemoteConnection('%s://%s:%s/gremlin' % (NEPTUNE_PROTOCOL, NEPTUNE_HOST, NEPTUNE_PORT),'g')
self.__g = self.__graph.traversal().withRemote(self.__remoteConn)
dotenv 사용하기에서 정의한 변수들을 os.getenv(변수명)을 통해 가지고 와야한다. 이 변수들을 사용해 Neptune DB와 연결할 수 있다. 또한 self.__g는 연결한 Neptune DB 인스턴스를 순회하기 위해 필요한 변수로 이후 대부분의 메소들에서 사용되므로 별도의 변수로 지정했다.
이렇게 기본적인 설정과 Neptune 연결을 마쳤다. 이를 바탕으로 gremlin-python 패키지에서 제공하는 기본적인 모듈을 사용해 보다 편리한 접근이 가능한 메소드들을 만들어볼 수 있다.
4. 메소드 정의하기
Neptune 데이터베이스에 데이터를 삽입하고 조회하기 편리한 메소드들을 별도로 만들었다. 데이터 삽입/조회의 경우 작업이 잦게 이루어졌기 때문에 GraphdbController 객체를 사용하는 쪽에서 코드의 중복이 이루어지지 않도록 별도로 정의했다. 또한 쿼리에 관련된 코드와 쿼리 실행이 포함된 비즈니스 로직을 코드 상 분리하고 싶었기 때문이다.
Vertex 삽입 및 조회
먼저 노드를 삽입할 수 있는 메소드를 정의했다.
# vertex 추가 메소드
def add_vertex(self, vertex_name, vertex_id = None, **kwargs):
if vertex_id is None:
vertex = self.__g.addV(vertex_name)
else:
vertex = self.__g.addV(vertex_name).property(T.id, vertex_id)
for prop in kwargs:
vertex = vertex.property(prop, kwargs[prop])
vertex = vertex.next()
return vertex
vertex를 추가할 때 label, 즉 vertex_name을 필수로 지정하도록 했고, vertex_id는 선택적으로 지정할 수 있도록 만들었다. 또한 **kwargs를 통해 필요한 속성들을 vertex에 추가하도록 했다. 만약 vertex_id를 매개변수로 입력하지 않으면 id가 String으로 자동생성되고 id를 입력할 경우 property(T.id, vertex_id)에 따라 id가 지정된다.
같은 vertex_id를 갖는 vertex가 있을 경우 추가되지 않도록 처리하고 싶어 먼저 id로 vertex를 조회하는 메소드를 추가했다.
# vertex 조회 메소드
def get_vertex(self, vertex_id):
vertex = self.__g.V(vertex_id).toList()
if not vertex:
return None
return vertex[0]
위의 get_vertex 메소드를 활용하여 add_vertex 메소드를 수정하였다.
# vertex 추가 메소드 완성
def add_vertex(self, vertex_name, vertex_id = None, **kwargs):
if vertex_id is None:
vertex = self.__g.addV(vertex_name)
else:
existing_vertex = self.get_vertex(vertex_id)
if existing_vertex is not None:
return existing_vertex
vertex = self.__g.addV(vertex_name).property(T.id, vertex_id)
for prop in kwargs:
vertex = vertex.property(prop, kwargs[prop])
vertex = vertex.next()
return vertex
Edge 삽입 및 조회
같은 방식으로 Edge도 id로 조회할 수 있는 메소드를 먼저 추가했다.
# edge 조회 메소드
def get_edge(self, edge_id):
edge = self.__g.E(edge_id).toList()
if not edge:
return None
return edge[0]
이를 활용해 edge를 추가하는 메소드를 구현했다.
# edge 추가 메소드
def add_edge(self, from_id, to_id, edge_name, edge_id = None, **kwargs):
if edge_id is None:
edge = self.__g.V(from_id).addE(edge_name).to(to_id)
else:
existing_edge = self.get_edge(edge_id)
if existing_edge is not None:
return existing_edge
edge = self.__g.V(from_id).addE(edge_name).to(self.__g.V(to_id)).property(T.id, edge_id)
for prop in kwargs:
edge = edge.property(prop, kwargs[prop])
edge = edge.next()
return edge
add_edge 메소드는 add_vertex 메소드와 크게 다른 것은 없지만 edge가 시작하는 vertex의 id와 edge가 끝나는 vertex의 id를 필수 매개변수로 설정한 것이 차이점이다. 이를 통해 edge는 두 vertex 사이를 연결하게 되는 것이다.
Vertex와 Edge 삭제
데이터를 다루다보면 vertex와 edge를 삭제하는 경우도 있는데 이를 위한 메소드 또한 추가했다. id를 매개변수로 받아 해당 id를 가진 vertex/edge를 삭제하도록 했다.
# vertex 삭제
def remove_vertex(self, vertex_id):
self.__g.V(vertex_id).drop().iterate()
# iterate()를 붙이지 않아도 실행될 것임
# edge 삭제
def remove_edge(self, edge_id):
self.__g.V(edge_id).drop().iterate()
# iterate()를 붙이지 않아도 실행될 것임
next()와iterate()의 차이점은 https://stackoverflow.com/a/47408276를 참고하도록 하자.
기타 메소드 정의
데이터를 추가하거나 주기적으로 업데이트하는 과정에서 위의 메소드 외에도 다른 쿼리를 실행할 필요가 있었다. 따라서 이런 쿼리들을 별도의 메소드로 만들었다.
property, 즉 속성 값으로 edge나 vertex를 조회하거나 label로 조회해야 할 일이 생겼다. 그래서 아래와 같은 메소드들을 정의했다.
먼저 vertex를 property 값으로 조회하기 위한 메소드이다.
# property 값으로 vertex 조회
def get_vertex_by_property(self, prop_name, prop_value):
vertex = self.__g.V().has(prop_name, prop_value).toList()
return vertex
위와 같은 방식으로 property에 따라 edge를 조회하도록 메소드를 정의할 수 있을 것이다.
label값을 기준으로 조회가 가능하다는 특성을 활용해 다음과 같은 메소드를 정의할 수 있다.
# 특정 vertex에서 뻗어져나간 edge들 중 특정 label을 가진 edge 조회하기
def get_edges_by_edge_name(self, from_id, edge_name):
edges = self.__g.V(from_id).outE(edge_name).toList()
return edges
# 특정 vertex에서 뻗어져나간 edge들 중 특정 label을 가진 edge와 연결된 vertex 조회하기
def get_vertices_by_edge_name(self, from_id, edge_name):
vertices = self.__g.V(from_id).out(edge_name).toList()
return vertices
이 외에도 개발 중 다른 쿼리가 필요해 아래와 같은 메소드들을 별도로 작성했다.
# 특정 vertex에서 뻗어져나간 edge들 중 특정 id를 가진 edge와 연결된 vertex 조회하기
def get_vertex_by_edge_id(self, from_id, edge_name, edge_id):
vertex = self.__g.V(from_id).outE(edge_name).hasId(edge_id).inV().toList()
if len(vertex) == 0:
return None
return vertex[0]
# 특정 vertex의 property에 해당하는 value 조회
def get_value_of_vertex_by_property_name(self, vertex, property_name):
value = self.__g.V(vertex.id).values(property_name).next()
if value is None:
return None
return value
(꼭 위와 같은 방식들로 메소드를 정의하지 않아도 되고, 필요에 따라 다르게 메소드를 작성하면 된다. 쿼리문 작성 참고는 Gremlin Tinkerpop Recipe)
클래스와 메소드 사용하기
나는 기존 RDB에 있는 데이터들 중 필요한 부분을 Neptune DB에 넣는 작업을 진행했다. 이 작업을 진행할 때 위에서 정의한 클래스와 메소드를 사용했다.
먼저 RDB의 video_reviews 테이블에 영상 리뷰들이 저장되어 있고, keywords 메뉴 키워드들이 foreign key인 영상 리뷰 id와 함께 저장되어있다. 즉 한 영상 리뷰는 여러 개의 keyword를 가질 수도 있고 갖지 않을 수도 있다. 이 관계를 그래프 데이터베이스로 표현하고자 했고 이러한 관계를 neptune db에 넣기 위해 위에서 정의한 메소드들을 활용했다.
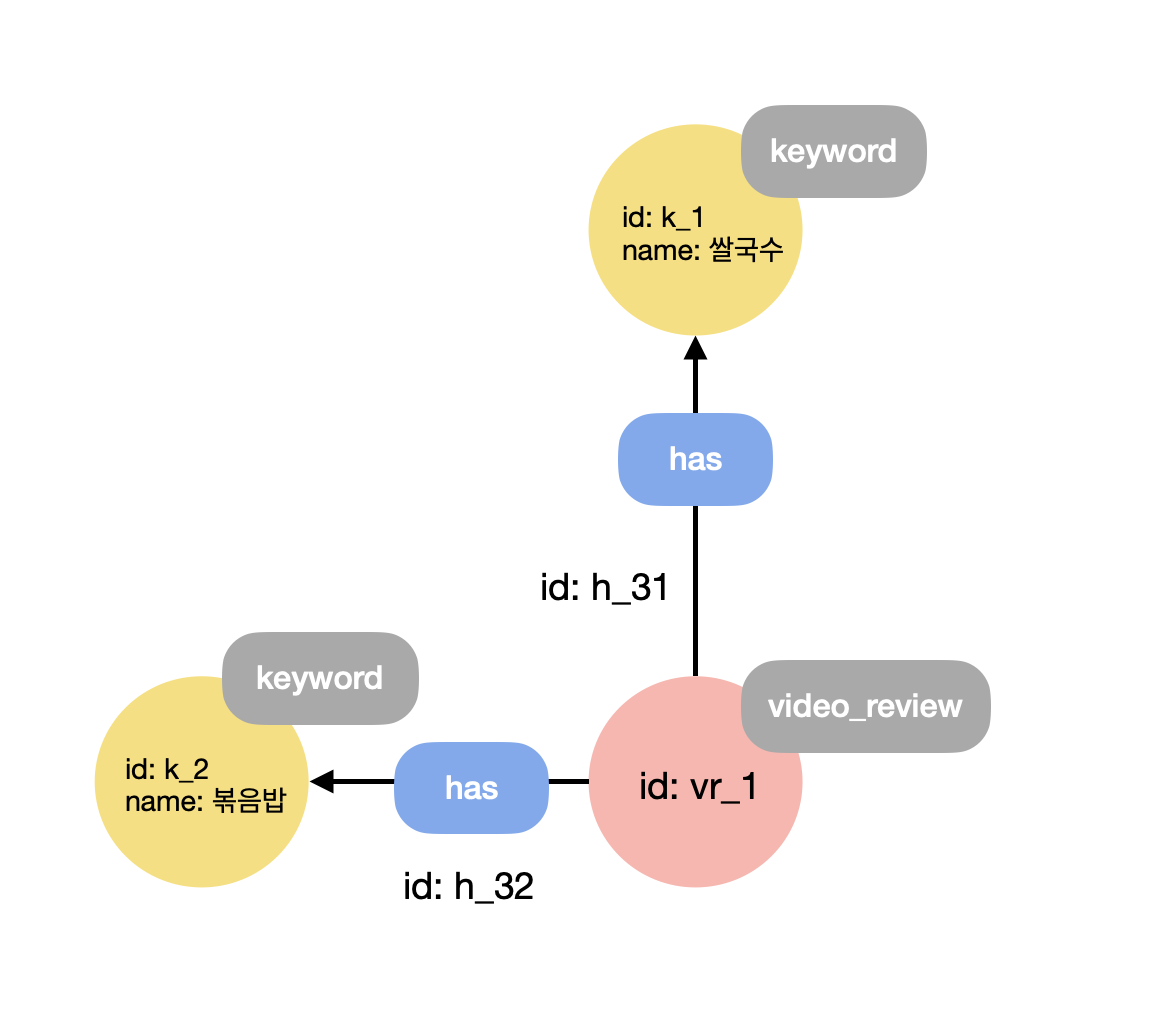 기존 RDB 키워드 테이블에서는 중복되는 이름의 키워드들이 있어서, unique한 키워드 이름에 따라 vertex를 생성할 것을 계획했다.또한 edge에도 별도의 id를 부여했는데, 이는 RDB 키워드 테이블에서 (키워드 이름, 영상 리뷰 id) 쌍이 갖는 고유 id 값을 활용했다.
기존 RDB 키워드 테이블에서는 중복되는 이름의 키워드들이 있어서, unique한 키워드 이름에 따라 vertex를 생성할 것을 계획했다.또한 edge에도 별도의 id를 부여했는데, 이는 RDB 키워드 테이블에서 (키워드 이름, 영상 리뷰 id) 쌍이 갖는 고유 id 값을 활용했다.
| id | video_review_id | keyword |
|---|---|---|
| 31 | 1 | 쌀국수 |
| 32 | 1 | 볶음밥 |
| 33 | 2 | 쌀국수 |
위의 표대로 라면 id가 k_1인 vertex에 vr_1 vertex 뿐만 아니라 vr_2 또한 연결되어 있어야 할 것이다. 이러한 방식으로 데이터 삽입을 진행했다.
1. Vertex 삽입하기
먼저 RDB에 저장되어 있는 영상 리뷰를 vertex로 삽입하기 위한 코드이다.
VIDEO_REVIEW_PREFIX = 'vr_'
db_controller = DbController()
graphdb_controller = GraphdbController()
def insert_video_reviews():
'''
db 내 모든 video reviews 에 대한 vertices 추가
'''
video_reviews = db_controller.select_from_table(table = 'VideoReview', columns = ['id'], order = 'id')
for video_review in video_reviews:
vertex_id = "%s%s" % (VIDEO_REVIEW_PREFIX, video_review.id)
vertex = graphdb_controller.add_vertex('video_review', vertex_id = vertex_id)
다음은 keyword, 즉 메뉴들을 vertex로 삽입했다. 삽입하기 전에 고유한 이름의 키워드가 저장될 수 있도록 unique_keywords 배열을 만들었다. id는 삽입 순서에 따라 증가하는 형태로 부여했다.
KEYWORD_PREFIX = 'k_'
def insert_keywords():
'''
db 내 모든 unique한 keywords 에 대한 vertices 추가
'''
keywords = db_controller.select_from_table(table = 'Keyword', columns = ['video_reviews_id', 'name'])
unique_keywords = list(set([keyword.name for keyword in keywords]))
count = 1
for unique_keyword in unique_keywords:
vertex_id = "%s%s" % (KEYWORD_PREFIX, count)
vertex = graphdb_controller.add_vertex('keyword', vertex_id = vertex_id, name = unique_keyword)
count += 1
2. Edge 삽입하기
위의 단계를 통해 RDB에 저장되어 있는 모든 keyword와 video_review 데이터를 Neptune DB에 vertex로 삽입했다. 이 vertex 간에 관계를 삽입하기 위해 edge를 추가하는 코드를 작성했다.
HAS_PREFIX = 'h_'
def insert_edges_between_video_and_keyword():
'''
db 내 모든 video reviews와 keywords 간의 관계(edge) 추가
'''
video_reviews = db_controller.select_from_table(table = 'VideoReview', columns = ['id'])
for video_review in video_reviews:
video_reviews_id = video_review.id
keywords = db_controller.select_from_table(table = 'Keyword', columns = ['id', 'name'], video_reviews_id = video_reviews_id)
video_vertex_id = "%s%s" % (VIDEO_REVIEW_PREFIX, video_reviews_id)
for keyword in keywords:
keyword_vertex_id = graphdb_controller.get_vertex_by_property('name', keyword.name)[0].id
edge_id = "%s%s" % (HAS_PREFIX, keyword.id)
edge = graphdb_controller.add_edge(from_id = video_vertex_id, to_id = keyword_vertex_id, edge_name = 'has', edge_id = edge_id)
영상마다 특정 영상이 갖고 있는 키워드들을 찾아 has label을 가진 edge로 연결되게끔 했다.
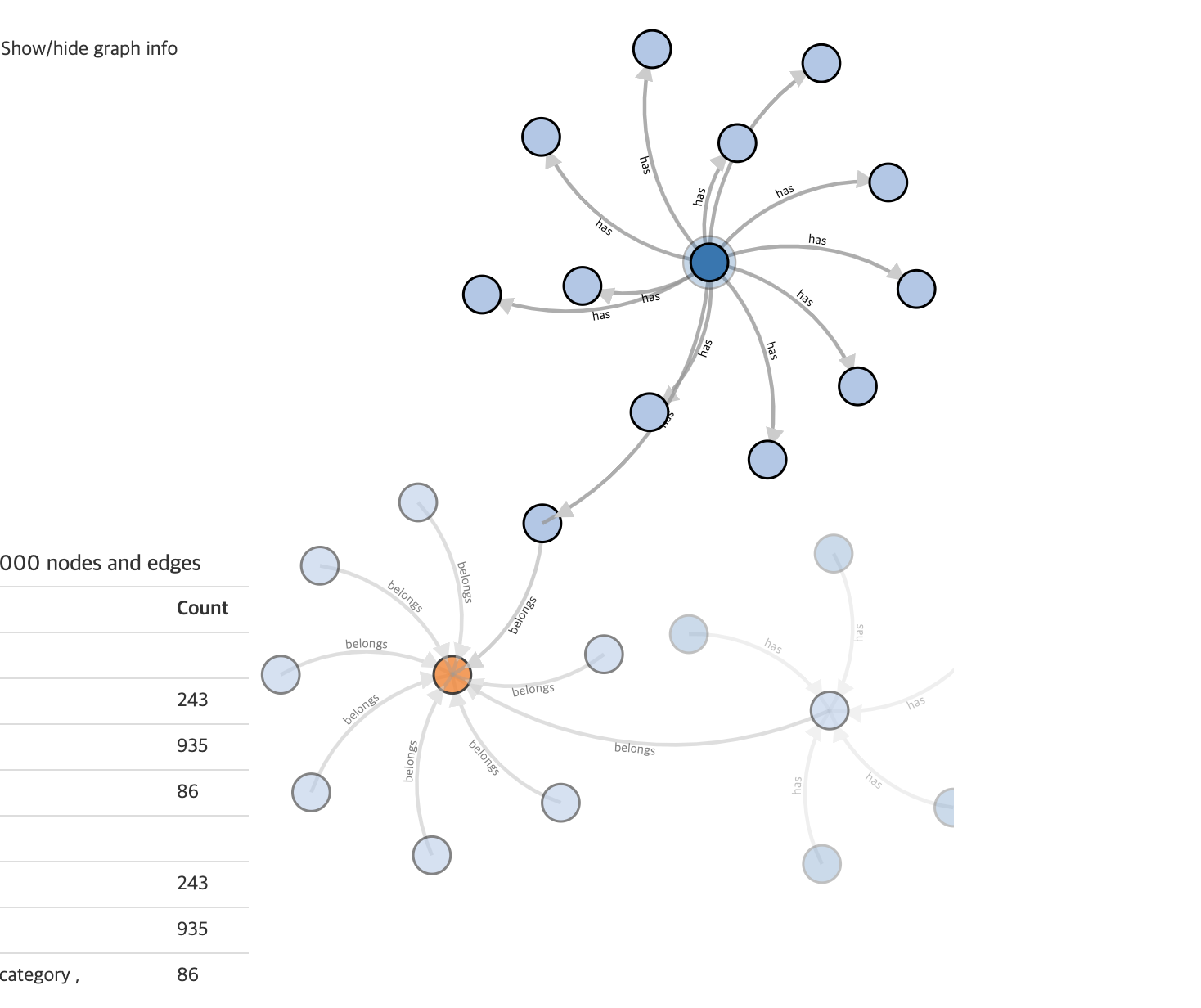
이 외에도 다른 label을 가진 vertex와 edge를 더 추가하여 그래프 데이터베이스를 구축했다. 아래 그림은 중간 단계에서 데이터베이스를 시각화한 것이다.(시각화 방법은 다음에 정리해서 올려볼 생각이다)
마치며
Gremlin과 관련된 자료가 많지 않아 구글링하면 너무 제한된 정보들만 떠서 절망스러울 때도 있었지만, 웬만한 기본적인 쿼리들은 Gremlin Tinkerpop Recipe에서 찾을 수 있었다. 하지만 이 페이지에서 찾은 쿼리를 Python에서 쓸 때는 추가적으로 뭔가를 써야 하는 경우도 있었는데, 그럴 땐 설치한 gremlin-python 패키지 코드를 뒤져보기도 했다ㅠㅠ
이 글에서는 Python을 사용해 Neptune DB에 연결하고 쿼리를 실행하는 것만을 다루었지만, Python 외에도 다른 언어로 Gremlin을 사용하여 Neptune DB에 엑세스할 수 있다. 내가 진행한 프로젝트의 경우, 그래프 데이터베이스를 순회하는 것은 Node.js에서 작업했다. Node.js에 연결한 과정은 다음에 비교적 간단하게 포스팅해보려 한다.
기나긴 글 끝!
Leave a comment