
@Async로 맛본 스프링 프록시
메서드가 비동기적으로 동작하는 원리에 대한 글은 아니다. 스프링에서
@Async를 사용할 때 어떤 과정을 거쳐 원래 메서드 대신 ‘비동기적으로 동작하는 메서드’가 실행되는지 알아본 글이다.
들어가며
이번에 회사에서 ‘작업 요청 기능’을 새롭게 개발하게 되었다.
어드민 페이지에서 “이런 저런 작업이 필요해요. 이거 처리해주세요!” 라는 요청을 남기면, 작업자 앱에서 요청을 확인하고 처리할 수 있는 기능이다. 처음에는 어드민에서 이 작업 지시를 생성하고, 작업자 앱에서 작업 지시를 확인하는 기능만 뚝딱 만들었다.
별거 없네!
그런데 이 “작업 요청” 기능은 일을 빠르게 처리하기 위함이라, 작업 요청이 생성되었을 때 관계자들이 이를 빠르게 확인할 수 있다면 더욱 좋을 것 같았다. 그래서 작업 요청이 생성되었을 때 관계자들에게 빠르게 알릴 수 있는 부가 기능을 넣어보기로 했다. 회사 내부 관계자에게는 슬랙으로 알림을 주고, 작업자에게는 작업자 앱으로 푸시 알림을 주는 방식으로.
작업 요청을 생성하는 코드에 이 두 로직을 추가하면 되겠다! 간단한걸! 이라 생각하며 뚝딱의 길로 들어섰다.
@Service
@RequiredArgsConstructor
public class WorkInstructionService {
// 생략
// 각종 repository, domain service 주입
@Transactional
public void createWorkInstruction(Long memberId, String vehicleId, String description, WorkInstructionType instructionType, LocalDateTime requestAt) {
Vehicle vehicle = getVehicle(vehicleId);
Member instructMember = getMember(memberId);
WorkInstructionEntity workInstruction = WorkInstructionEntity.builder()
.member(instructMember)
.vehicle(vehicle)
.description(description)
.instructionType(instructionType)
.requestAt(requestAt)
.build();
workInstructionRepository.save(workInstruction);
// 여기까지가 기존 작업 요청 생성 코드
// ====================================================================
// 새롭게 추가한 코드
Region contractedRegion = vehicle.getContractedRegion();
List<Employee> employees = getEmployeesOfContractedRegion(contractedRegion);
List<String> appPushIds = employees.stream()
.map(Employee::getAppPushId)
.collect(Collectors.toList());
sendSlackNotification(workInstruction);
sendPushNotification(appPushIds, workInstruction);
logPushNotification(appPushIds, workInstruction);
}
}
어떤 문제가 있었냐면요
찝찝함을 안고
슬랙으로 알림을 보내는 친구와 푸시 알림을 보내는 친구를 각자 역할에 맞게 잘 추상화해둔 덕분에 추가하는 코드 자체는 단순했다. 그런데 마음 한 켠에 약간의 찝찝함이 있었다.
- 작업 요청을 생성하는 데 있어서 필수적인 로직이 아닌데, 여기에 같이 있어도 되는걸까?
- 부가 기능이 실패하면 작업 요청 생성도 롤백될텐데, 이러면 좀 곤란하겠군…
이런 찝찝함을 안고 개발 환경에 배포해보았다. 코드는 문제없이 동작했다. 그런데 앱 푸시 요청을 보내고 성공 여부를 받아오는 데까지 생각보다 오랜 시간이 걸렸다. 대략 100ms 내외에 처리되던 생성 api가 3-4초까지 걸리는 경우가 생겨버렸다.
이건 좀 아닌 것 같다. 작업 요청 생성하는 데 3초나 걸리면 안되는데..?? 🤯
요구사항 다시 쓰기
부가 기능을 처리하는 시간이 작업 요청 생성 api 응답 시간에 영향을 주고 있었다. 이 영향을 없애고자 부가 기능을 기존 코드에서 분리해내보기로 했다. 이 참에 마음 한 켠에 안고 있던 찝찝함도 해소할 수 있을 것 같았다.
나름대로 변경해본 요구사항은 아래와 같다.
- 작업 요청을 생성하는 코드에서는 작업 요청 생성에 필수적인 로직만 처리한다.
- 부가 기능에 실패해도 작업 요청 생성은 성공해야 한다. (롤백되면 안됨)
- 부가 기능을 실행하는 데 걸리는 시간이 작업 요청 생성 api 응답 시간에 영향을 주지 않아야 한다.
많이들 아는 이야기, 스프링 이벤트로 해결해보자.
먼저, 1번과 2번 요구사항을 만족시키기 위해서 “이벤트 발행” 방식을 사용하기로 했다. 작업 요청 생성 코드에서는 필수적인 로직만 처리하고, 부가 기능은 작업 요청이 생성되었다는 이벤트가 발행되면 처리하는 방식이다. 이렇게 하면 ‘작업 요청 생성’과 ‘알림’ 로직을 분리하고 각 코드에서는 단일한 책임만을 가지게 된다.
이벤트 발행 / 소비를 구현하기 위해 스프링에서 제공하는 ApplicationEventPublisher를 사용했다.
먼저, ‘작업 요청 생성 완료’ 라는 이벤트를 정의했다.
@Data
@AllArgsConstructor
public class WorkInstructionCreatedEvent {
private final Vehicle vehicle;
private final String description;
private final WorkInstructionType instructionType;
private final Member instructMember;
private final LocalDateTime requestAt;
}
그리고 작업 요청 생성 코드에서는 위에서 정의한 이벤트를 발행하도록 했다.
@Service
@RequiredArgsConstructor
public class WorkInstructionService {
private final ApplicationEventPublisher eventPublisher;
// 생략
// 각종 repository, domain service 주입
@Transactional
public void createWorkInstruction(Long memberId, String vehicleId, String description, WorkInstructionType instructionType, LocalDateTime requestAt) {
Vehicle vehicle = getVehicle(vehicleId);
Member instructMember = getMember(memberId);
WorkInstructionEntity workInstruction = WorkInstructionEntity.builder()
.member(instructMember)
.vehicle(vehicle)
.description(description)
.instructionType(instructionType)
.requestAt(requestAt)
.build();
workInstructionRepository.save(workInstruction);
// 이벤트 발행
eventPublisher.publishEvent(new WorkInstructionCreatedEvent(
vehicle,
description,
instructionType,
instructMember,
requestAt
));
}
}
이렇게 ‘작업 요청 생성 완료’ 이벤트를 발행하면, 구독하는 곳에서 이벤트를 소비해 부가 기능을 처리할 수 있다.
해당 이벤트를 구독하는 Listner 를 아래와 같이 추가했다.
Listner에서 슬랙 알림을 보내는 로직, 푸시 알림을 보내는 로직, 로그를 남기는 로직을 구현함으로써
각 코드에서 단일한 책임을 가지게끔 했다. (1번 요구사항 만족 ✅)
WorkInstructionService: 작업 요청을 생성하는 책임WorkInstructionCreatedListener: 작업 요청 생성 완료를 외부로 알리는 책임
@Component
@RequiredArgsConstructor
public class WorkInstructionCreatedListener {
// 생략
// 각종 의존성 주입
@Transactional(propagation = Propagation.REQUIRES_NEW)
@TransactionalEventListener(phase = TransactionPhase.AFTER_COMMIT)
public void handleWorkInstructionCreatedEvent(WorkInstructionCreatedEvent event) {
Region contractedRegion = event.getVehicle().getContractedRegion();
List<Employee> employees = getEmployeesOfContractedRegion(contractedRegion);
List<String> appPushIds = employees.stream()
.map(Employee::getAppPushId)
.collect(Collectors.toList());
sendSlackNotification(event);
sendPushNotification(appPushIds, event);
logPushNotification(appPushIds, event);
}
}
위와 같이, @TransactionalEventListener(phase = TransactionPhase.AFTER_COMMIT)
애노테이션으로 트랜잭션 커밋 이후에 이벤트를 처리하도록 했다.
이렇게 하면 부가 기능 처리에 실패하더라도 작업 요청 생성 트랜잭션이 롤백되지 않게 된다. (2번 요구사항 만족 ✅)
사내에서 앱 푸시 알림을 성공적으로 보낸 경우 RDB에 기록해두고 있다.
logPushNotification()이 위 역할을 수행하는데, 이 과정을 트랜잭션으로 묶어서 처리하고자@Transactional애노테이션을 추가했다. 하지만TransactionPhase=AFTER_COMMIT옵션을 주었기 때문에, 같은 트랜잭션 내에서는 더이상 새로운 커밋을 허용하지 않는다. 따라서 새로운 트랜잭션 내에서 로그를 남길 수 있도록@Transactional(propagation = Propagation.REQUIRES_NEW)옵션을 추가했다.
API 응답 시간은 그대로인데?
스프링 이벤트를 사용해 1번과 2번 요구사항을 만족시킬 수 있었다. 하지만, 다시 테스트를 해보아도 작업 요청 생성 api 응답 시간은 여전히 느려진 상태였다.
이유는 요청을 처리하는 스레드에 있었다. @EventListener는 이벤트를 발행한 스레드에서 같이 실행된다.
아래 사진과 같이, 이벤트를 발행한 Service와 이벤트를 구독하는 Listener가 같은 스레드에서 실행되고 있었다.

스프링에서는 한 스레드에서 요청을 처리하고 응답을 반환하는데, 같은 스레드에서 이벤트 구독 작업까지 수행한다면 해당 작업이 끝날 때 까지 스레드가 블록되어 응답을 반환하지 못하는 것이다.
즉, 부가 기능을 실행하는 데 걸리는 시간이 api 응답 시간에 영향을 주지 않으려면 ‘요청을 처리하는 스레드’와 ‘이벤트를 구독해 부가 기능을 처리하는 스레드’를 분리해야 한다.
이를 위해 스프링에서 제공하는 @Async 애노테이션을 사용해보기로 했다.
@Async로 해결해보자.
Spring Framework 공식 문서 에 나와 있는 설명을 보면
Annotation that marks a method as a candidate for asynchronous execution. Can also be used at the type level, in which case all the type’s methods are considered as asynchronous.
라고 되어있다. @Async 애노테이션을 붙이면 해당 메서드는 ‘비동기로 실행될 수 있는 후보’가 된다.
즉, @Async 메서드를 호출한 곳에서 @Async 메서드가 실행되는 것을 기다리지 않으며
@Async 메서드는 별도의 스레드에서 비동기적으로 실행된다.
그래서 아래와 같이 @Async 애노테이션을 붙이고 테스트를 해보았다.
Listener가 다른 스레드에서 실행될 것을 기대했지만, 여전히 같은 스레드에서 실행되고 있었다.
public class WorkInstructionCreatedListener {
// 생략
// 각종 의존성 주입
@Async
@Transactional(propagation = Propagation.REQUIRES_NEW)
@TransactionalEventListener(phase = TransactionPhase.AFTER_COMMIT)
public void handleWorkInstructionCreatedEvent(WorkInstructionCreatedEvent event) {
// 생략
}
}

찾아보니, @Configuration 클래스에 @EnableAsync 애노테이션을 붙여야 비동기적으로 동작할 수 있다고 한다.
그래서 @EnableAsync 애노테이션을 붙이고 다시 테스트를 해보았을 때,
Listener가 다른 스레드에서 실행되는 것을 확인할 수 있었다.
@EnableAsync
@SpringBootApplication
public class SampleApplication {
public static void main(String[] args) {
SpringApplication.run(SampleApplication.class, args);
}
}
// ===============================
@Component
public class WorkInstructionCreatedListener {
// 생략
// 각종 의존성 주입
@Async
@Transactional(propagation = Propagation.REQUIRES_NEW)
@TransactionalEventListener(phase = TransactionPhase.AFTER_COMMIT)
public void handleWorkInstructionCreatedEvent(WorkInstructionCreatedEvent event) {
// 생략
}
}

해결은 했다. 그런데 이거 어떻게 동작하는거지?
@Async만 붙였을 때에는 비동기적으로 동작하지 않고, @EnableAsync를 붙여야 비동기적으로 동작함을 확인했다.
왜 @EnableAsync를 붙여야 하는지, 어떤 과정을 거쳐서 메서드 호출이 비동기적으로 동작하는 것인지 궁금해졌다.
(이 글을 쓰게 된 이유이기도 하다.)
이것저것 찾아보다가, https://dzone.com/articles/effective-advice-on-spring-async-part-1 에서 아래와 같은 설명을 찾았다.
When you put an Async annotation on a method underlying it, it creates a proxy of that object where Async is defined (JDK Proxy/CGlib) based on the proxyTargetClass property. Then, Spring tries to find a thread pool associated with the context to submit this method’s logic as a separate path of execution.
@Async 애노테이션을 붙이면 해당 메서드를 감싸는 프록시 객체가 생성되고,
스프링은 해당 메서드를 별도의 스레드에서 실행할 수 있도록 스레드 풀을 찾아서 메서드를 실행한다고 한다.
프록시? 스레드 풀을 언제 찾는거지? 잘 이해가 가지 않아서 직접 코드를 까보았다. 🛠️
코드 까보기
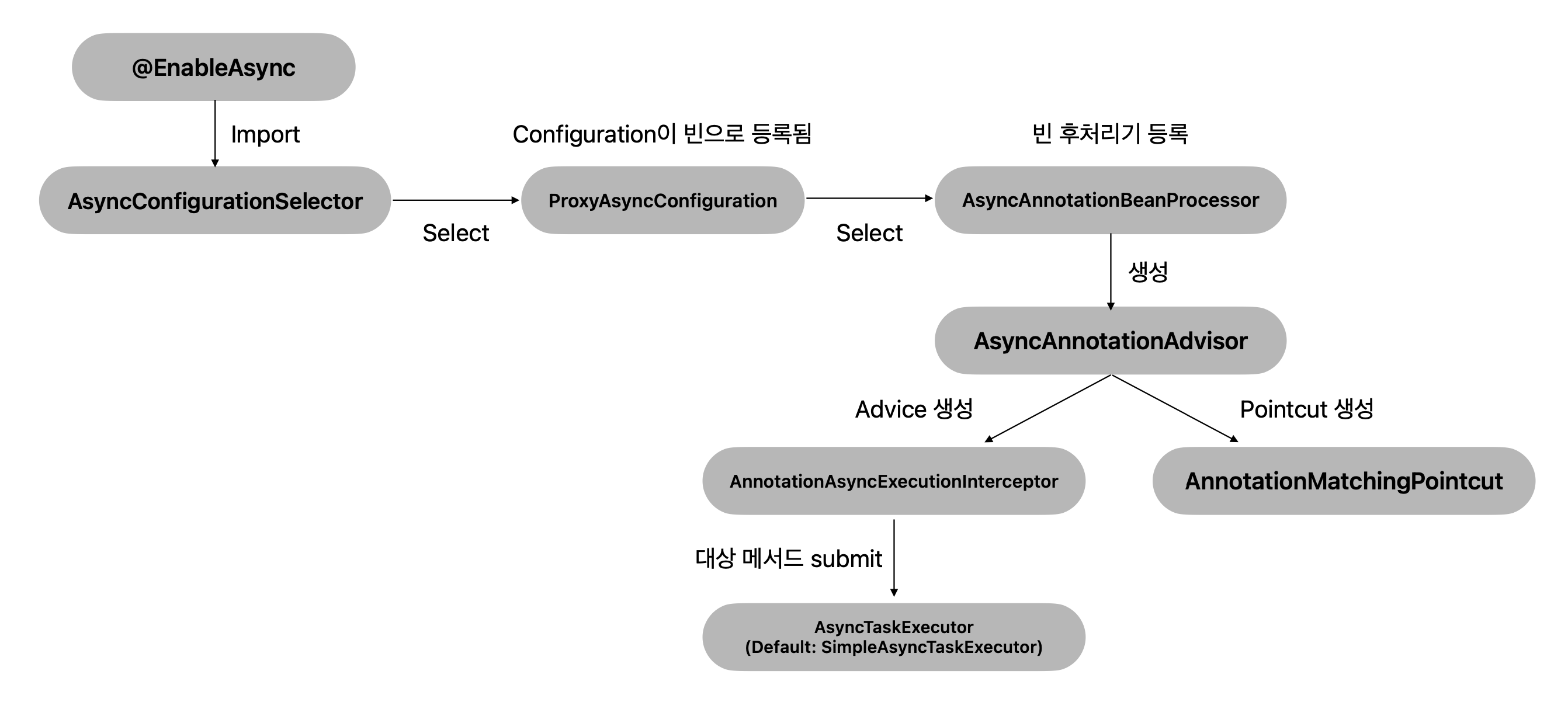
먼저 @EnableAsync 애노테이션이 정의된 코드를 찾아 들어가보았다.
1. @EnableAsync
@Target(ElementType.TYPE)
@Retention(RetentionPolicy.RUNTIME)
@Documented
@Import(AsyncConfigurationSelector.class)
public @interface EnableAsync {
Class<? extends Annotation> annotation() default Annotation.class;
boolean proxyTargetClass() default false;
AdviceMode mode() default AdviceMode.PROXY;
int order() default Ordered.LOWEST_PRECEDENCE;
}
@EnableAsnyc 코드를 보면, @Import 애노테이션을 통해 AsyncConfigurationSelector를 import하고 있다.
AsyncConfigurationSelector 클래스 이름으로만 보았을 때, 아래와 같은 역할을 예상할 수 있었다.
@EnableAsync애노테이션을 붙였을 때 Async와 관련된Configuration을 추가하는 역할을 할 것 같다.- 조건에 따라 서로 다른
Configuration을 선택하는 역할을 할 것 같다.
아래는 AsyncConfigurationSelector 클래스의 코드이다.
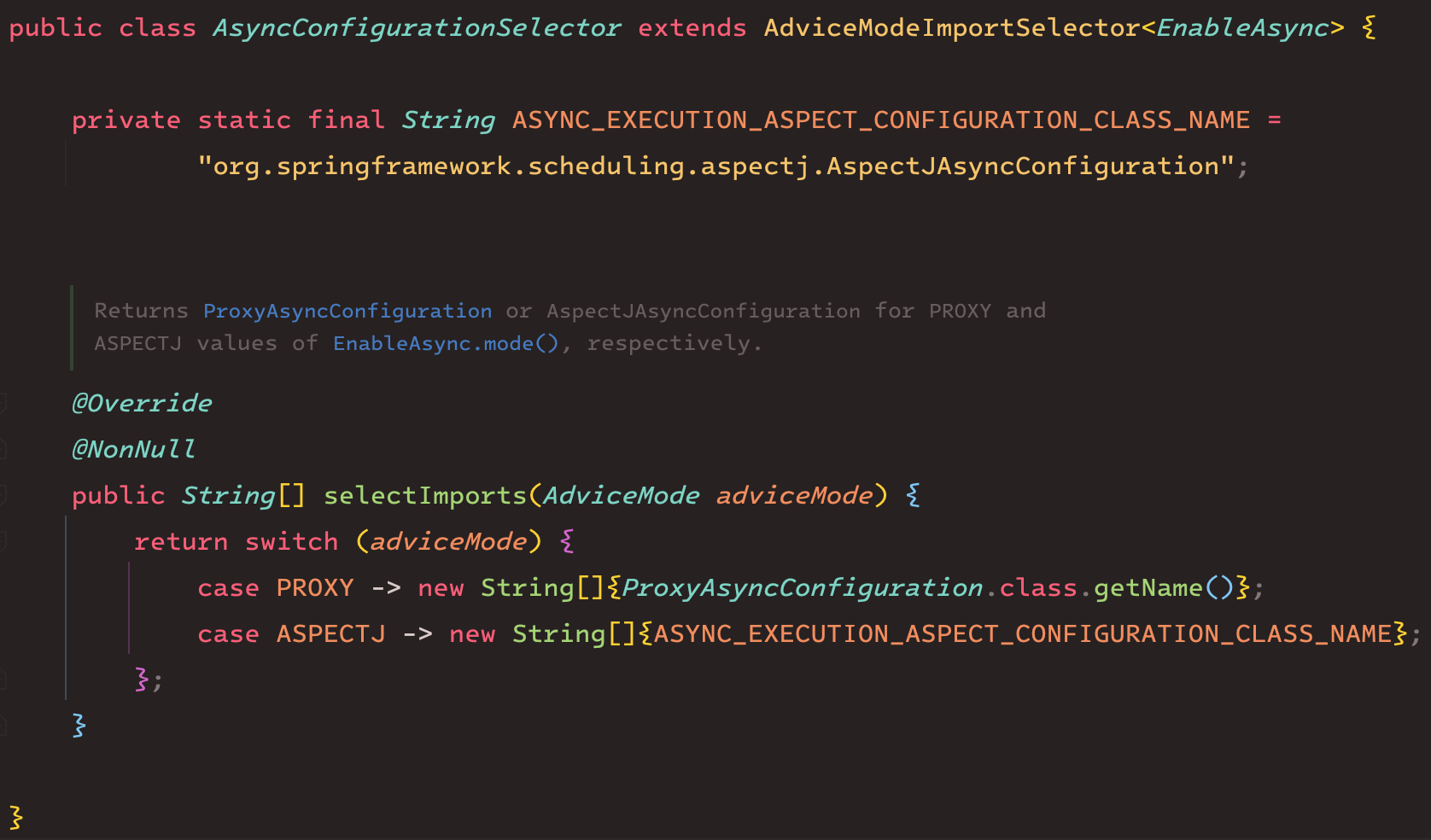
예상했던 바와 같이, 조건에 따라 서로 다른 Configuration 을 선택하는 역할을 수행하고 있었다.
AdviceMode에 따라 다른 Configuration 을 추가하는데,
기본적으로 @EnableAsync 에서는 아래 코드에서 확인할 수 있듯이 AdviceMode.PROXY가 기본값으로 설정되어 있다.
따라서 기본값으로 ProxyAsyncConfiguration를 import하게 된다.
// @EnableAsync 코드 일부
AdviceMode mode() default AdviceMode.PROXY;
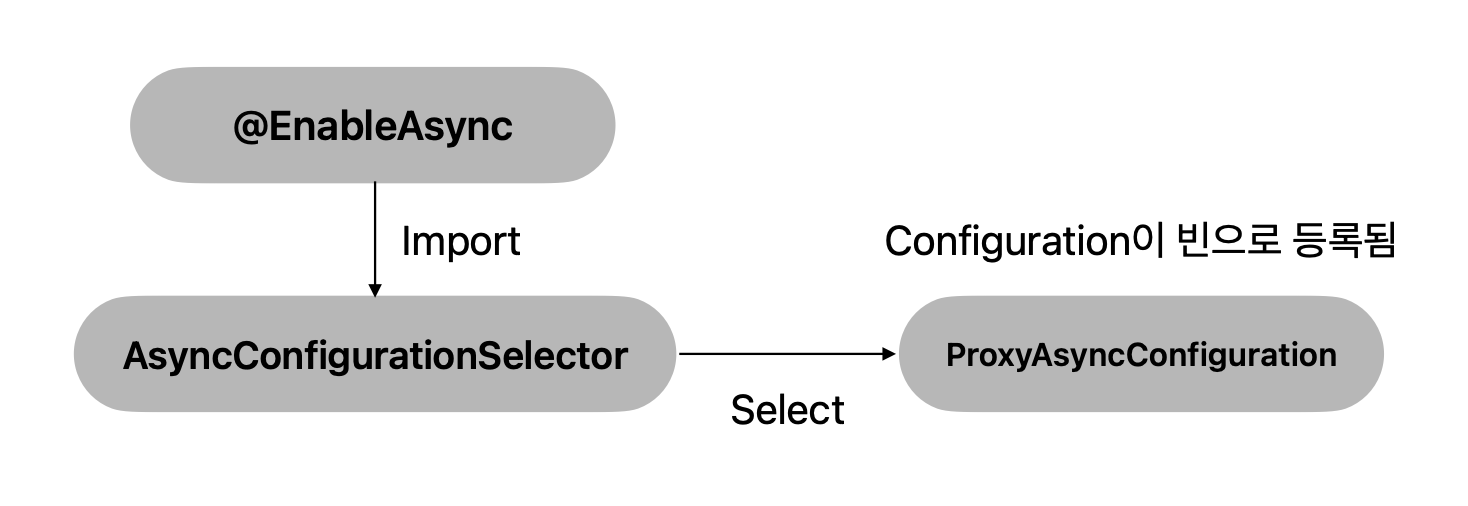
2. ProxyAsyncConfiguration
위에서 @EnableAsync를 통해 ProxyAsyncConfiguration가 import되는 것을 확인했다.
그럼 ProxyAsyncConfiguration에서는 어떤 일을 할까?
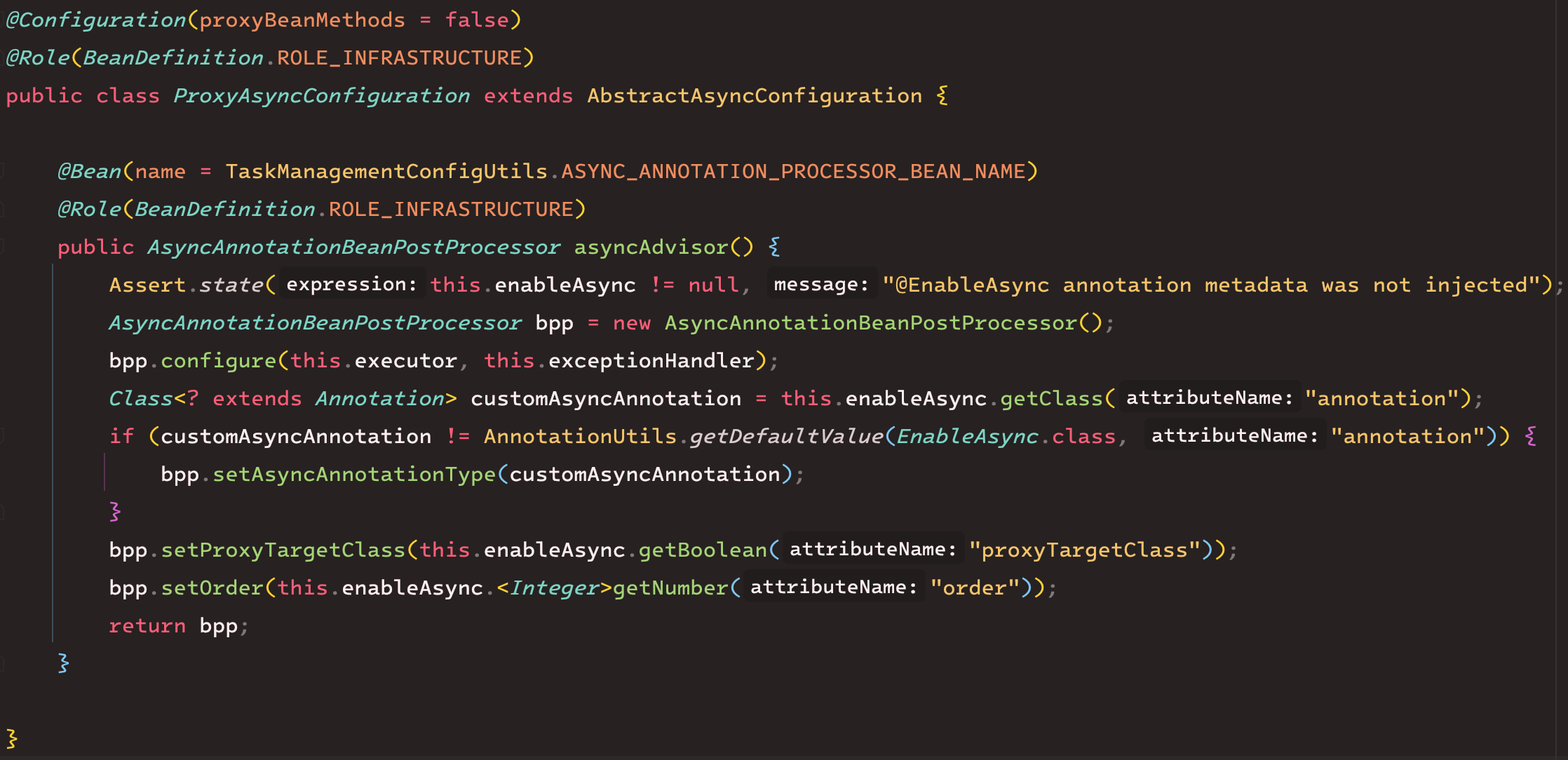 코드를 확인해보면
코드를 확인해보면 AsyncAnnotationBeanPostProcessor를 빈으로 등록하고 있다.
“빈 후처리기” (BeanPostProcessor)는 스프링 빈 저장소에 특정 빈을 등록하기 전에 조작한다.

BeanPostProcessor의 등장
여기서 잠깐, BeanPostProcessor가 뭔지 알아보자.
A 객체가 있고 이를 호출할 때 로깅을 더하는 상황을 생각해보자.
단순히 A 객체를 생성하는 코드에 로깅을 추가하면 된다.
하지만 이 로깅을 추가하는 부분이 A 객체를 생성하는 코드에 들어가지 않게 하려면 어떻게 해야 할까?
프록시 개념을 사용하면 이런 상황을 해결할 수 있다.
A 객체를 생성하는 코드에 추가적인 동작을 넣지 않고, A 객체를 감싸는 프록시 객체를 생성한다.
그리고 프록시 객체에서는 A 객체의 메서드를 호출하기 전에 추가적인 동작을 수행하고, A 객체의 메서드를 호출한다.
A 객체의 메서드를 호출하는 곳에서는 A 객체를 직접 호출하는 것처럼 보이지만, 실제로는 프록시 객체를 호출하게끔 만든다.
이렇게 하면 ‘추가적인 동작’을 A 객체 생성 코드에 넣지 않아도 되며, A 객체를 직접 호출하는 것처럼 사용할 수 있다.
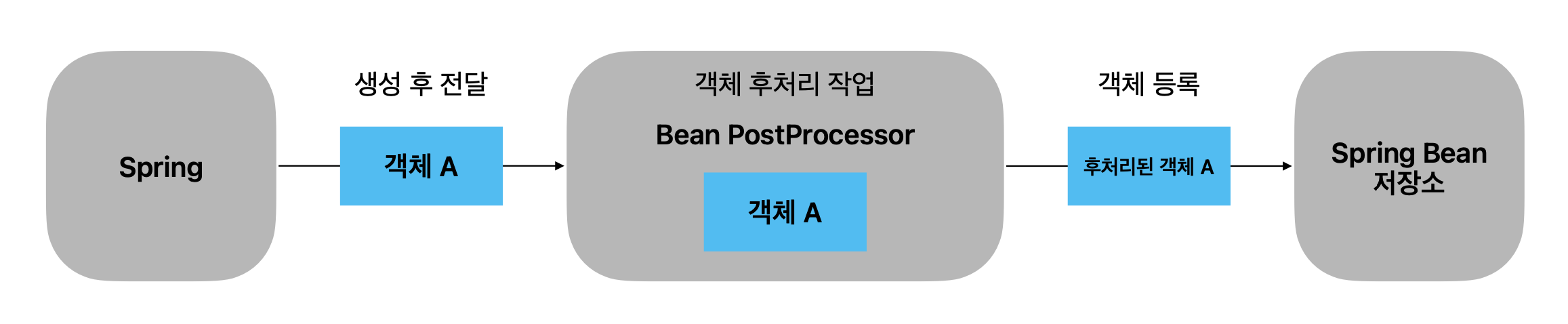
갑자기 왜 프록시에 대해 이야기를 하냐면, BeanPostProcessor는 프록시를 생성하는 데 사용될 수 있기 때문이다.
앞서 언급한 것처럼 BeanPostProcessor는 특정 빈을 조작한 뒤 스프링 빈 저장소에 등록할 수 있다.
위의 예시에 적용해본다면, A 객체를 빈으로 등록하는 대신 A 객체를 적당히 조작해 프록시 객체를 생성한뒤 이를 빈으로 등록할 수 있는 것이다.
즉, BeanPostProcessor를 사용하면 프록시 객체를 실제 객체 대신 빈으로 등록할 수 있다.
3. AsyncAnnotationBeanPostProcessor
ProxyAsyncConfiguration 에서 AsyncAnnotationBeanPostProcessor를 빈으로 등록했다.
빈 후처리기 역할에 따라, 실제 객체가 ‘비동기적으로 수행될 수 있도록’ 조작해 프록시 객체를 생성하고 이를 빈으로 등록할 것이라 예상해볼 수 있었다.
그럼 AsyncAnnotationBeanPostProcessor는 어떤 방식으로 프록시 객체를 생성하는 걸까?
AsyncAnnotationBeanPostProcessor 클래스의 메서드를 보면 이 빈 후처리기가 하는 일을 크게 세가지로 정리해볼 수 있다.
- Executor 설정
- annotation type 설정
- AsyncAnnotationAdvisor 생성
3-1. Executor 설정
 이 메서드는 위의
이 메서드는 위의 ProxyAsyncConfiguration에서 BeanPostProcessor를 등록할 때 호출한다.
Executor를 설정해주고 있는데, 이 Executor가 무엇인지는 아래에서 다뤄보겠다.
3-2. annotation type 설정

@EnableAsync 애노테이션에서 annotation 속성을 설정할 수 있었는데
이 속성을 ProxyAsyncConfiguration에서
bpp.setAsyncAnnotationType(customAsyncAnnotation) 를 통해 beanPostProcessor에 전달하고 있다.
빈 후처리기에서 하는 일을 생각해보았을 때, 빈 후처리기가 “어떤 애노테이션이 붙은 메서드를 프록시로 만들 것인지” 결정하기 위한 정보를 전달하는 것으로 보인다.
예상대로 동작하는지도 아래에서 확인해보겠다.
3-3. AsyncAnnotationAdvisor 생성
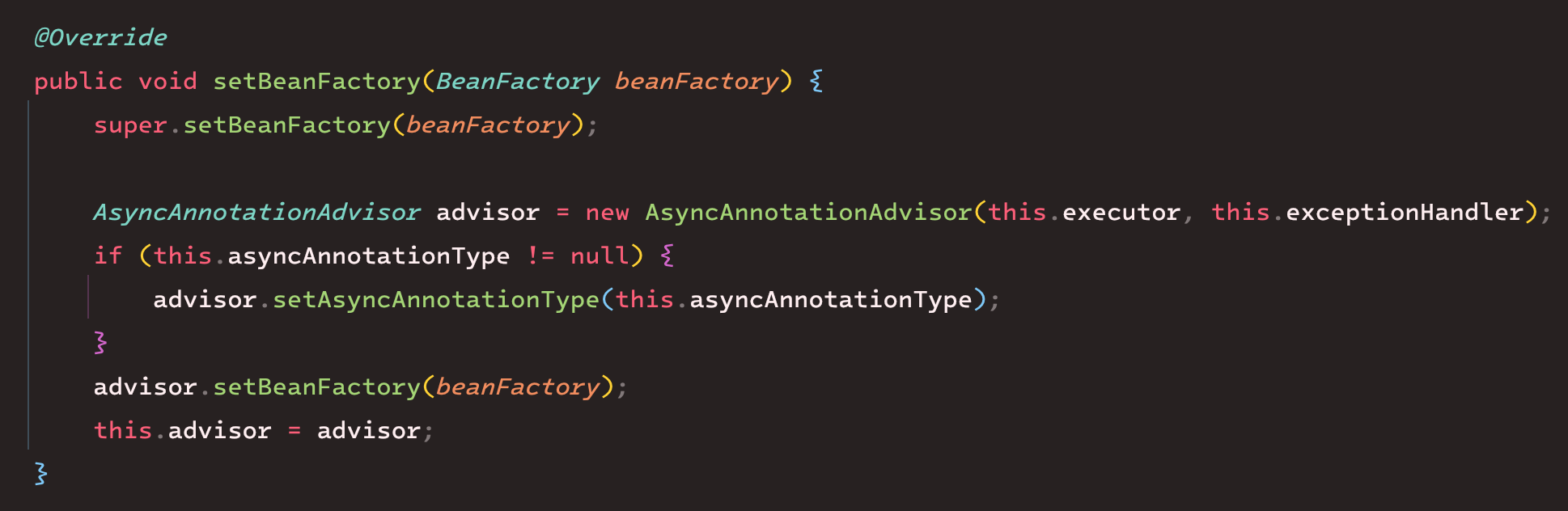
setBeanFactory 에서 AsyncAnnotationAdvisor를 생성하고 있다.
Advisor 는 어떤 역할을 수행하길래 빈 후처리기에서 AsyncAnnotationAdvisor가 필요한 것인지 궁금해졌다.
Advisor의 등장
Spring Framework 공식 문서 - Advisor
에서 Advisor에 대해 아래와 같이 설명하고 있다.
Base interface holding AOP advice (action to take at a joinpoint) and a filter determining the applicability of the advice (such as a pointcut).
Advisor는 Pointcut이라는 친구를 통해 어떤 조인포인트에 어떤 부가 기능(Advice)을 적용할지 결정한다.
먼저, Pointcut은 어디에(조인포인트) 부가 기능을 추가할 것인지 결정하는 역할을 수행한다.
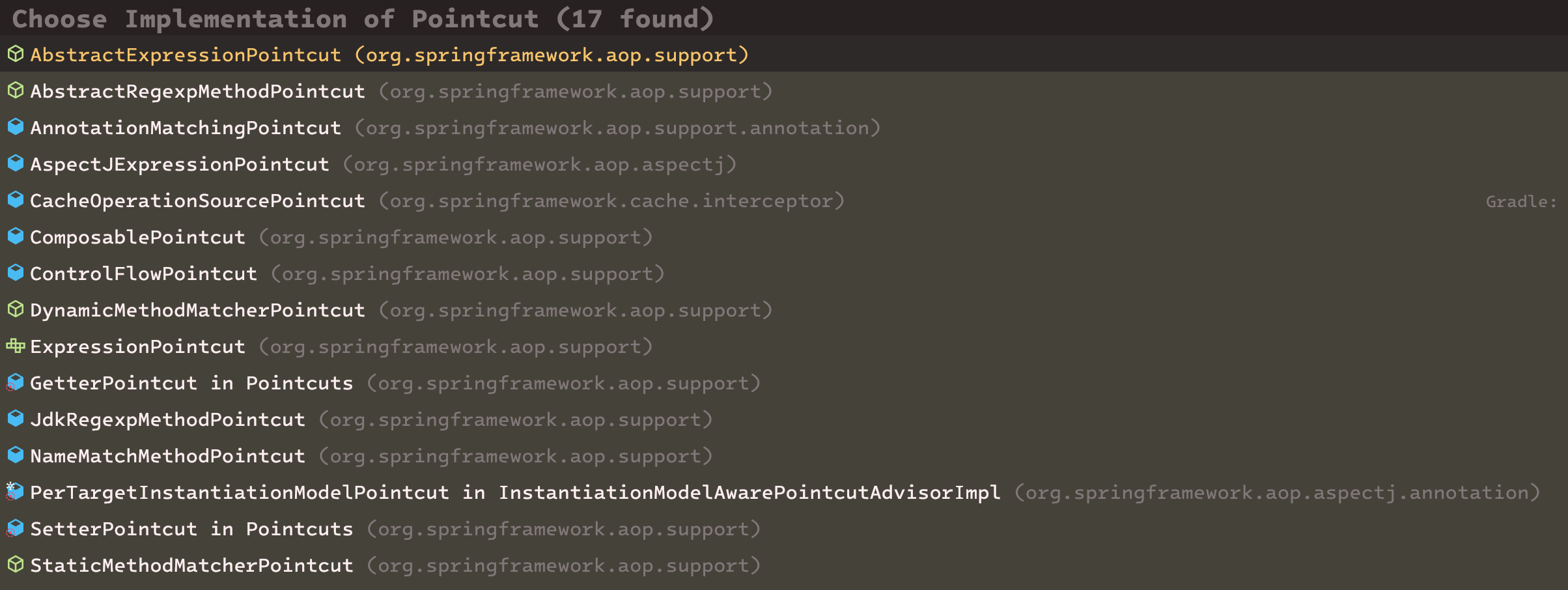
Pointcut 인터페이스를 구현한 클래스들은 위와 같다.
메서드 이름이나 애노테이션 이름 등으로 조인포인트를 찾아낼 수 있도록 Pointcut 구현체를 스프링에서 제공해주고 있다.
Advice는 어떤 부가 기능을 추가할 것인지 결정하는 역할을 수행한다.
A 객체 예시로는, 로깅을 추가하는 역할을 Advice가 수행하게 될 것이다.
스프링의 Advisor는 하나의 Pointcut과 하나의 Advice를 가지고 있어,
어디에 어떤 부가 기능을 추가할 것인지 정보를 알고 있다.
마찬가지로 AsyncAnnotationAdvisor도 Advisor를 구현하고 있으므로, 어디에 어떤 부가 기능을 추가할 것인지 정보를 알고 있다.
즉, ‘어떤 객체’(pointcut 역할)를 ‘비동기로 동작할 수 있는 기능을 추가’(advice 역할)할 것인지에 대해 알고 있고,
아마도 @Async 애노테이션이 붙은 메서드인 경우 ‘비동기로 동작할 수 있는 기능을 추가’해야 한다는 정보를 가지고 있을 것이다.
AsyncAnnotationAdvisor 에서 실제로 어떤 Pointcut과 Advice를 가지고 있는지 확인해보자.
4. AsyncAnnotationAdvisor
생성자에서 Advice와 Pointcut을 생성한다.
public AsyncAnnotationAdvisor(@Nullable Supplier<Executor> executor, @Nullable Supplier<AsyncUncaughtExceptionHandler> exceptionHandler) {
Set<Class<? extends Annotation>> asyncAnnotationTypes = new LinkedHashSet<>(2);
asyncAnnotationTypes.add(Async.class);
// 생략
this.advice = buildAdvice(executor, exceptionHandler);
this.pointcut = buildPointcut(asyncAnnotationTypes);
}
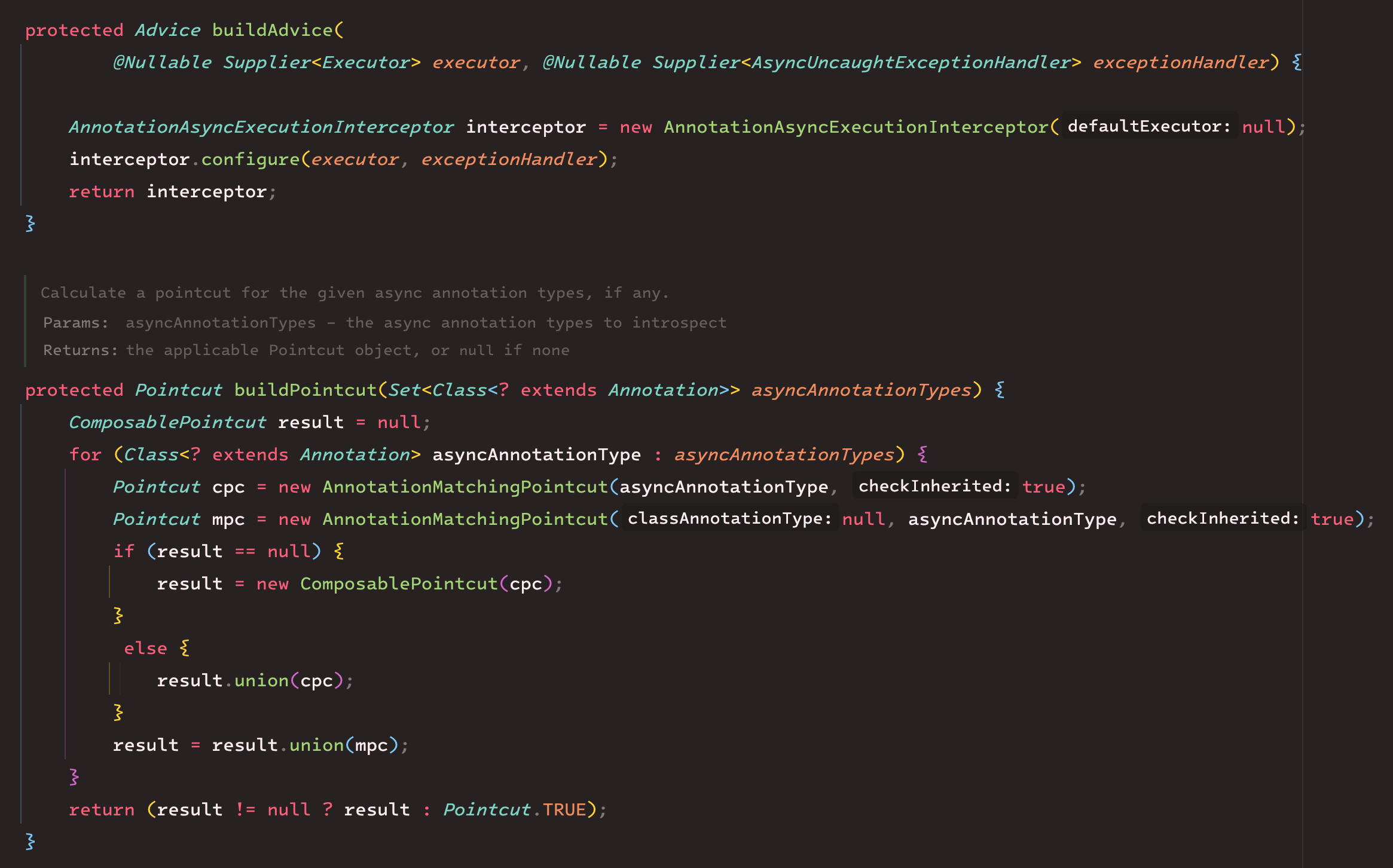
먼저, Pointcut을 생성하는 메서드에서는 Advisor 생성자에서 설정했던 annotationTypes를 가지고 AnnotationMatchingPointcut을 생성한다.
생성자에서 기본적으로 Async.class를 asyncAnnotationTypes에 추가했었다.
이 Async 클래스는 EventListener에서 사용했던 @Async 애노테이션이다.
즉, Pointcut 에서는 @Async 애노테이션이 붙은 메서드에 프록시를 적용한다는 정보를 갖게 된다.
Advice를 생성하는 메서드에서는 ProxyAsyncConfiguration에서 설정한 Executor와 ExceptionHandler를 가지고 AnnotationAsyncExecutionInterceptor를 생성한다.
이 AnnotationAsyncExecutionInterceptor는 Advice 를 구현하고 있다.
Advice는 어떤 부가 기능을 추가할 것인지를 정의하므로, AnnotationAsyncExecutionInterceptor의 코드를 확인하면
어떻게 메서드 호출이 비동기적으로 동작하는지 알 수 있을 것이다.
5. AnnotationAsyncExecutionInterceptor
AnnotationAsyncExecutionInterceptor는 AsyncExecutionInterceptor를 상속받고 있어, AsyncExecutionInterceptor 코드를 확인해보았다.
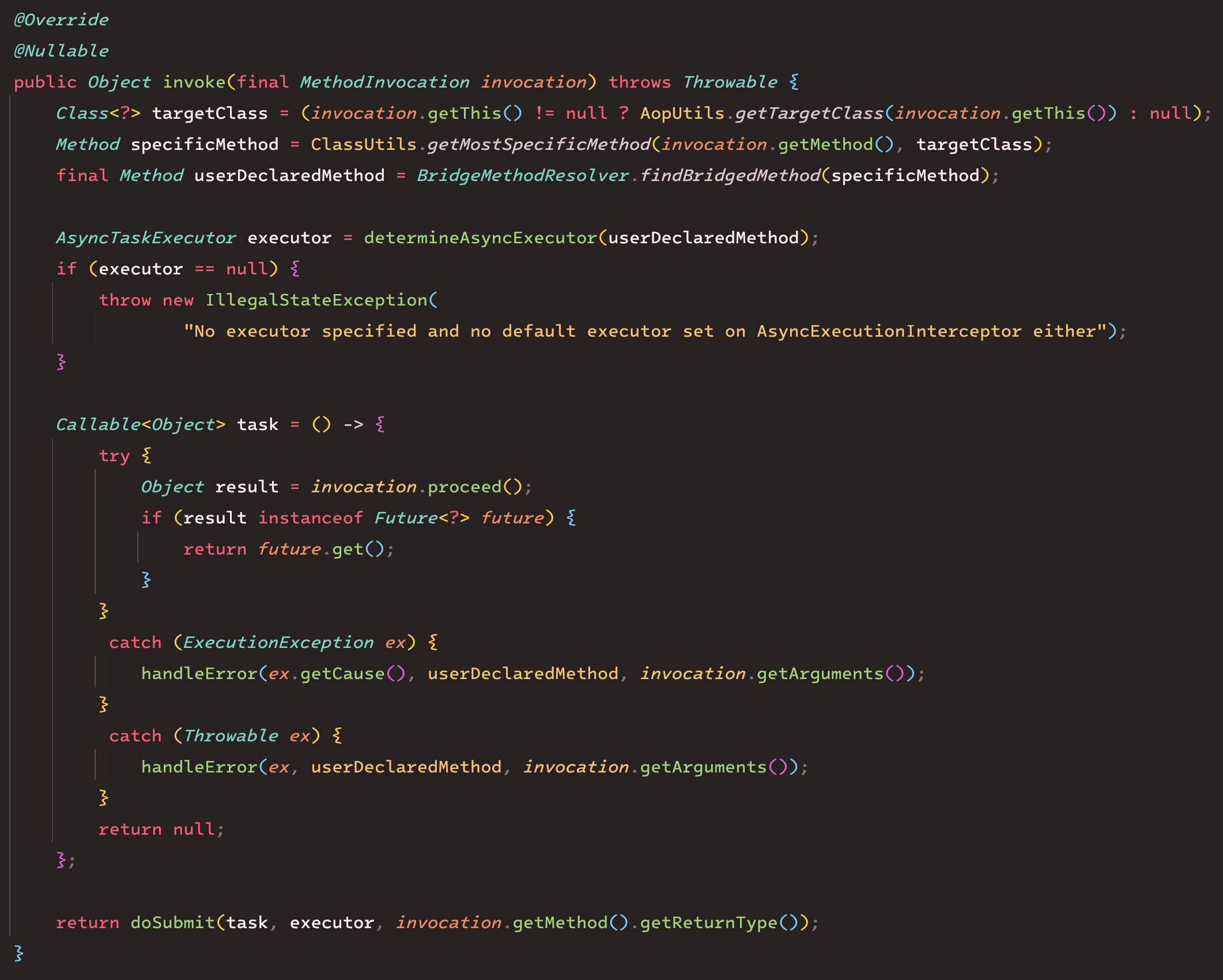
Inteceptor는 프록시 대상이 되는 메서드의 호출 전후에 수행할 작업을 정의한다. invoke 메서드를 구현해서 해당 작업을 정의할 수 있다.
구현 코드에서, 대상 메서드를 바로 호출하지 않고 Callable로 감싸서 doSubmit 메서드에 전달하고 있다.
doSubmit 메서드에 Callable 객체 뿐만 아니라 executor도 전달하고 있는데,
이 executor는 AsyncTaskExecutor를 구현한 객체여야 한다.
doSubmit을 통해,
AsyncTaskExecutor 구현체가 제공하는 별도의 스레드 풀에서 스레드를 할당받아 Callable을 실행하게 되고,
Callable은 대상 메서드를 실행하게 된다. 즉, 대상 메서드가 별도의 스레드에서 비동기적으로 실행될 수 있는 것이다.
AsyncTaskExecutor가 될 executor는 ProxyAsyncConfiguration에서부터 시작된다.
AsyncConfigurer를 구현한 객체가 빈으로 등록되어 있다면, 해당 빈을 executor로 사용하고 그렇지 않다면 기본적으로 SimpleAsyncTaskExecutor를 사용한다.
Spring Framework 공식 문서 - SimpleAsyncTaskExecutor
에 따르면, SimpleAsyncTaskExecutor는 각 작업에 대해 항상 새로운 스레드를 생성해 비동기적인 작업을 수행한다고 한다.
스레드 풀을 별도로 생성하지 않기 때문에, 스레드 재사용 및 스레드 풀링을 지원하려면 AsyncConfigurer를 별도로 구현해 빈으로 등록해야 한다.
이 글에서 ‘비동기’ 동작에 대한 상세를 다루려는 것은 아니라서
AsyncTaskExecutor에 대해 자세히 다루지는 않겠다.
정리
EventListener로 문제를 해결하던 중 @Async 가 새로운 요구사항(비동기 동작)을 만족할 수 있는 방법이 될 것 같아 이를 사용해보았다.
그런데 @Async만을 붙였을 때 메서드는 비동기적으로 동작하지 않았고,@EnableAsync 를 붙여야 비동기적으로 동작함을 확인했다.
어떻게 해서 @EnableAsync를 붙여야 비동기적으로 동작할 수 있는지 궁금해졌고, 코드를 확인해보면서 이에 대한 답을 찾아보았다.
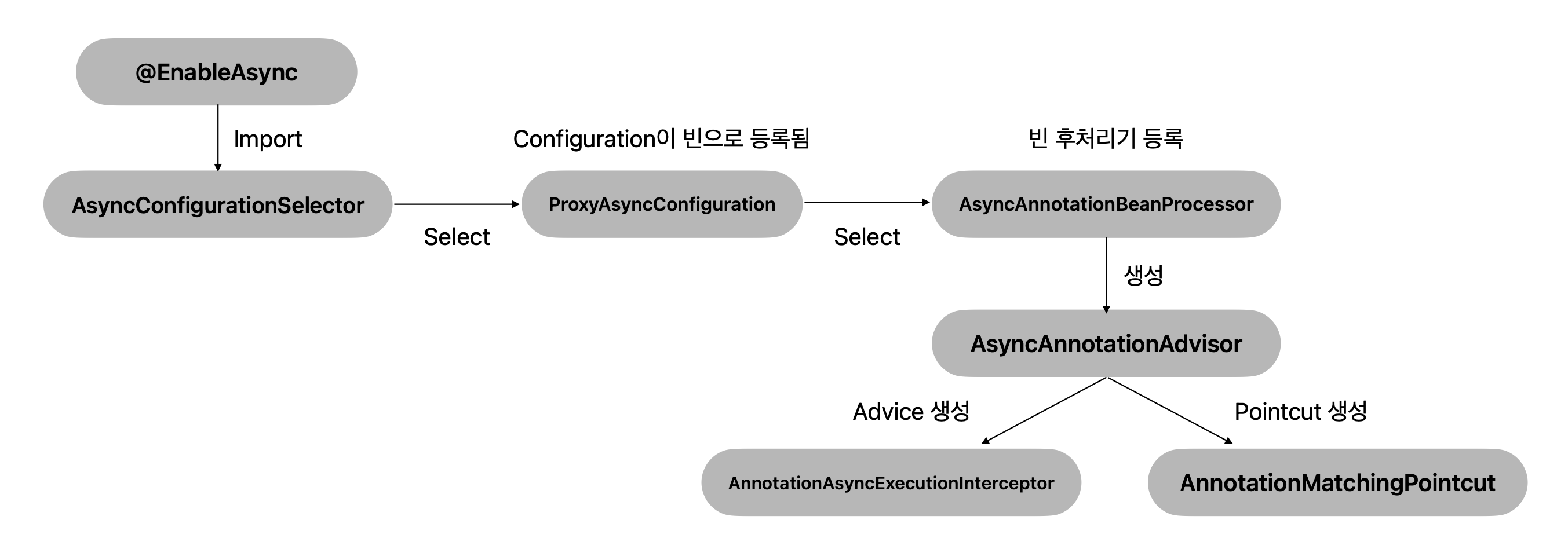
@EnableAsync를 붙이면AsyncAnnotationBeanPostProcessor가 빈으로 등록된다.AsyncAnnotationBeanPostProcessor는@Async애노테이션이 붙은 메서드를 찾아 프록시 객체를 생성한다.- 대상 메서드를
Callable로 감싸서AsyncTaskExecutor를 통해 비동기적으로 실행되도록 프록시 객체를 생성한다. (Advice) AsyncAnnotationBeanPostProcessor는 대상 메서드 대신 생성한 프록시 객체를 빈으로 등록한다.AsyncConfigurer를 구현한 객체가 빈으로 등록되어 있다면, 해당 빈을AsyncTaskExecutor로 사용하고 그렇지 않다면 기본적으로SimpleAsyncTaskExecutor를 사용한다.
마무리하며
글이 길어졌다. 왜 @Async를 사용하게 됐는지부터 쓰려다보니 생각보다 길다.
이번에 회사에서 새롭게 기능을 개발하면서 처음으로 @Async를 써본 거였다.
이게 어떻게 동작하는지 궁금해서 일단 코드부터 까봤는데, 처음엔 이해가 안됐다. 그래서 나름 스프링 프록시 인프런 강의도 들어보고, AOP도 조금 공부해봤다.
공부하고 나서 다시 코드를 보니 동작 방식이 점차 이해가 가는게 꽤나 즐거웠다…💪
참고
- https://dzone.com/articles/effective-advice-on-spring-async-part-1
- https://docs.spring.io/spring-framework/docs/current/javadoc-api/org/springframework/scheduling/annotation/Async.html
- https://docs.spring.io/spring-framework/docs/current/javadoc-api/org/springframework/aop/Advisor.html
- https://docs.spring.io/spring-framework/docs/current/javadoc-api/org/springframework/core/task/SimpleAsyncTaskExecutor.html
Leave a comment