
AWS NEPTUNE 적용기 (1)
프로젝트를 진행하면서 고군분투했던 Amazon Neptune. 이 친구를 어떻게 적용했고, 그 과정에서 어떤 걸 공부했는지 기록해두고 싶어 적용기를 써보기로 했다!
WHY Neptune?
Neptune을 도입하기까지, 근본적으로는 추천 기능을 프로젝트에 넣기까지 정말 많은 고민들이 있었다. 기획과 사용자 경험 측면에서 추천 기능의 필요성에 대해서 고민했고, 두 명이라는 한정된 인력과 한정된 시간 때문에 구현 방법에 대해서 고민했다.
우리 프로젝트에 추천 기능이 왜..?
프로젝트를 진행하면서 추천 기능에 대한 이야기가 여러 차례 오갔다. 추천 기능에 대한 논의가 여러 번 이루어졌음에도 불구하고 쉽게 추천 기능을 넣지 못했던 데에는 오버 엔지니어링에 대한 우려가 있었다.
우리에겐 최소 기능만 빠르게 개발하고자 하는 계획이 있었다. 추천 기능 말고도 개발할 게 태산이기도 했어서 추천 기능에 오랜 시간을 쏟을 수는 없었다. 추천 기능을 Collaborative Filtering 방식으로 구현한다거나 Contents Based Filtering과 같은 방식으로 구현하면 공부하고 적용하는 데 까지 너무 오랜 시간이 걸릴 것 같았다.
이렇게 오랜 시간을 써야할 만큼 추천 기능이 우리 프로젝트에 필요할까..
그래서 우리는 기획 의도에 맞게 UX를 다시 고민하면서 추가해야할 기능들과 작업들을 정리하는 시간을 가졌다. 우리 서비스는 연속적으로 스크롤하면서 콘텐츠를 소비하는 형태이기 때문에 콘텐츠의 로딩 순서가 사용자의 행동과 관련이 있어야 사용자가 오래 머무를 수 있을 것이라 판단했다. 그래서 우리는 사용자가 눌러본 키워드(메뉴)를 기반으로 콘텐츠를 추천해주는 기능을 도입하기로 했다.
그래프 데이터베이스 써보면 되겠는데?
사용자가 눌러본 키워드, 즉 “메뉴”를 기반으로 관련도가 높은 콘텐츠를 추천해주자! 는 것이 추천 기능의 첫 계획이었다. 메뉴라는 키워드 특성 상 키워드 간의 관계를 만들어낼 수 있고, 키워드 간 관계 뿐만 아니라 각 메뉴를 세부 식품군으로 분류할 수 있기 때문에 관계를 잘 정의한다면 연관성이 높은 데이터들을 찾아내기 용이할 것이라 생각했다.
갖고 있는 데이터 간의 관계를 잘 표현하고 이 관계를 잘 활용한다면 간단한 추천 기능 정도는 만들어 낼 수 있겠다!
멘토님께서 추천해주신 그래프 데이터베이스가 이러한 관계를 표현하는 데 적합할 것 같아 그래프 데이터베이스를 활용해보기로 결정했다.
그래프 데이터베이스로 Neo4j도 있지만, Amazon Neptune이 완전관리형 데이터베이스로 제공되기 때문에 환경 구축이 편리할 것 같아 Neptune을 선택했다. (꽤나 비싼 Neptune, 프로젝트 비용 지원 받을 때 써보자는 마음도 있었다ㅎㅎ)
Neptune을 적용하기에 앞서
그래프 데이터베이스란
그래프 데이터베이스는 관계를 저장하고 탐색하는 데 용이한 데이터베이스로, 일종의 NoSQL 데이터베이스다. 말 그대로 데이터를 그래프 방식으로 나타낸 것이라서, 특정 데이터 간의 관계를 직관적으로 확인할 수 있다.
그래프 데이터베이스를 구성하는 방법에는 몇 가지 방식이 있는데, 그 중 대표적인 것이 Property Graph Model이다. Property Graph Model의 데이터는 nodes, relationships, 그리고 properties로 구성된다.
node는 key-value 쌍으로 이루어진다. node는 하나 이상의 label을 가질 수 있는데 이 label에는 node의 유형을 정의할 수 있다.
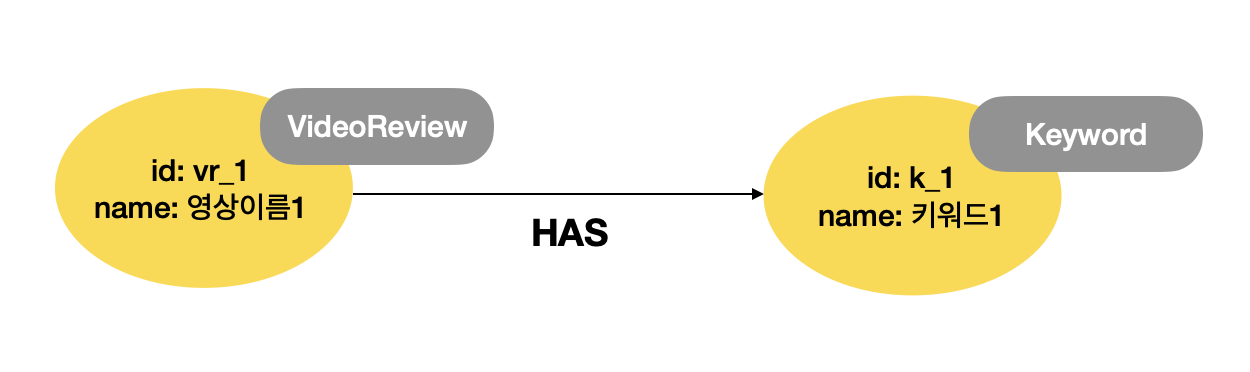
위 그림처럼, VideoReview는 한 노드의 label이고 id와 name은 key-value 가 쌍을 지어 노드의 속성을 정의하게 된다. Role/Type의 경우는 보통 label로 표현하고, 특정 노드의 특징을 표현하기 위해서는 property(속성)을 사용할 수 있다.
각 노드 간의 relationship은 위 그림의 화살표처럼 edge로 표현된다. edge는 방향을 가지고, node와 마찬가지로 edge도 label을 가질 수 있다. 노드 간 relationship에 가중치를 주고 싶거나 relationship의 quality를 표현하고 싶다면 node의 property처럼 edge에도 property를 부여하면 된다. property에 단순 가중치값 뿐만 아니라, 관계가 맺어진 시점을 나타내는 timestamp 같은 값도 속성으로 지정 가능하다.
관계형 데이터베이스에 빗대어 설명하면 label은 같은 성질의 데이터를 구조적으로 묶은 테이블에 해당하고, node는 하나의 행에 해당하며 property로 정의된 key-value 쌍은 RDB에서 column 이름과 실제 값에 해당한다.
| RDB | GraphDB |
|---|---|
| 테이블 | Label |
| 행 | node |
| 열/data | 속성/값 |
이렇게 구성된 그래프 데이터베이스는 직관적이기 때문에 데이터 간의 복잡한 관계를 빠르게 파악할 수 있다는 장점이 있다. 가령 빅데이터를 다룰 때, 관계형 데이터베이스는 외래키로 엔티티 사이의 관계를 표현하므로 복잡한 관계의 데이터일 경우 그 관계를 파악하기 어렵다. 이러한 경우 그래프 데이터베이스를 효과적으로 활용할 수 있다.
Amazon Neptune
Amazon Neptune는 아마존에서 제공하는 완전관리형 그래프 데이터베이스 서비스이다. 완전관리형(Fully-Managed)는 AWS가 모두 관리하는 형태로, 쉽게 백업과 가용성에 대한 부분을 보장받을 수 있다. 서비스 제공을 위한 인프라를 AWS에서 제공해주기 때문에 편리한 사용이 가능한데, Neptune 데이터베이스 서비스는 완전관리형이기 때문에 설치과정을 포함해 모니터링, 이벤트 알림, 데이터베이스 복제 등에 있어서 빠르고 편리하게 작업할 수 있다.
Neptune 데이터베이스에 쿼리를 실행하기 위해서는 Gremlin이나 SPARQL을 사용해야 한다. Neptune은 Property Graph 모델을 지원하며 Gremlin query language는 Property Graph를 빠르게 순회하는 방법을 제공한다. Property Graph 모델 뿐만 아니라 RDF(Resource Description Framework)도 지원하는데, 이 경우 SPARQL을 사용할 수 있는 것 같다..
Neptune은 보안을 위해 격리된 네트워크에 Neptune 서비스를 제공하는데, 이를 위해 Amazon VPC를 사용한다. (VPC 관련해서는 나중에 더 자세히 포스팅해보고자 한다) VPC를 통해 Neptune DB 인스턴스에 대한 엑세스를 제어할 수 있다.
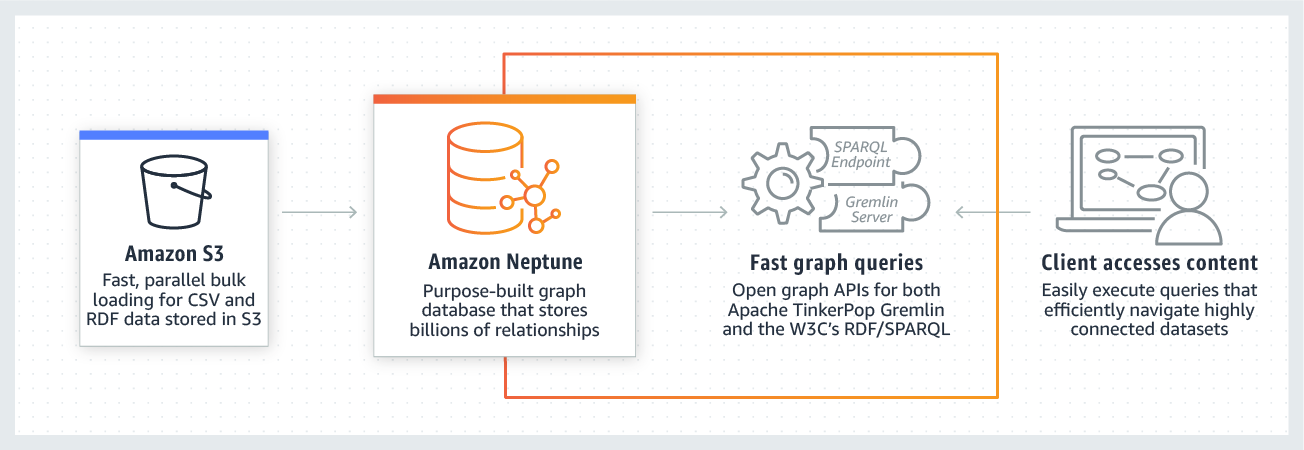 출처 https://aws.amazon.com/ko/neptune/
출처 https://aws.amazon.com/ko/neptune/
참조
Graph DB modeling 관련 github repo
Neo4j wikidocs
Amazon Neptune 공식 페이지
Neo4j developer guide
다음 포스트는 Neptune 환경 설정 과정을 담아보겠다!
Leave a comment