
Elastic Cloud 비용 절반으로 줄인 썰 🤑
들어가며
올해 초, 회사 계정으로 무서운 메일이 도착했다. “Your storage space is running low” 라며..
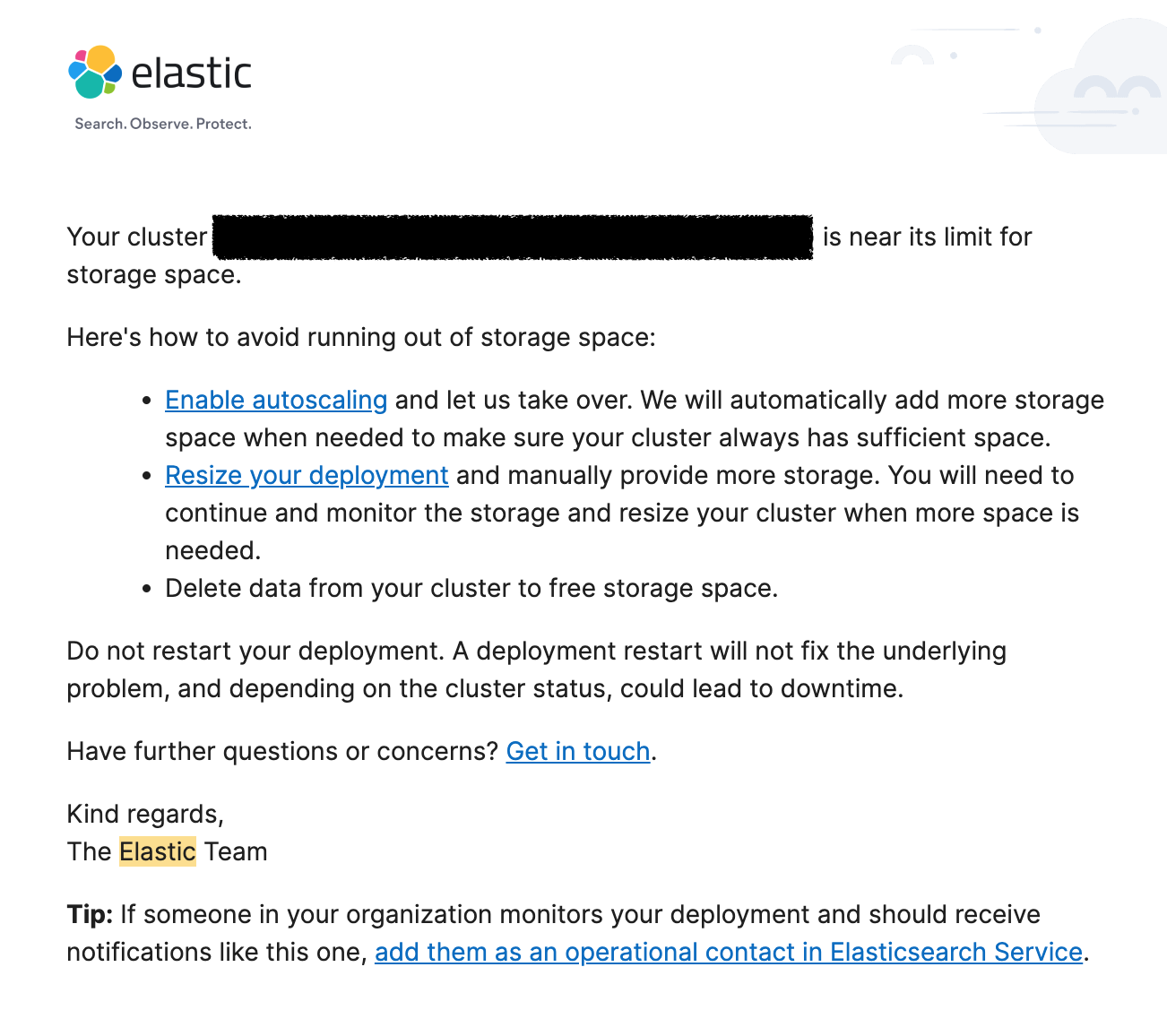
확인해보니 Elastic Cloud 핫 노드의 용량이 99%에 달하고 있었고, 이로 인해 데이터가 제대로 쌓이지 않고 있었다. 사내에서 사용하고 있던 핫 노드는 마스터 노드와 데이터 노드 역할을 모두 겸하고 있었기 때문에 전체 클러스터에 영향을 미치고 있었다.
급히 핫 노드 용량을 두 배로 늘려 상황을 정리했지만, 근본적인 문제를 해결하지 못한 탓에 용량을 원래대로 줄이지 못하고 있었다. 다른 조치 없이 용량만 줄이면 또 다시 데이터가 쌓이지 않는 문제가 재발할 것이 분명했다. 그렇게 핫 노드 용량은 두 배가 되고, 비용도 크게 늘어난 상태로 약간은 방치(?)되었다.
“엘라스틱 비용 정리해야 하는데..” 라는 마음의 짐을 짊어진 채로 몇개월이 지났다. 3분기가 끝나가며, 이제는 정말로 비용을 정리해야 할 때가 왔다는 팀 리더의 판단이 있었다.
그렇게 Elastic Cloud 비용 정리를 시작하게 되었다.
어떻게 비용을 줄일 것인가
공식 문서에서 제안하는 방법
위에서 늘려뒀던 핫 노드의 용량을 정리하는 것 외에 다른 방법으로도 비용을 줄일 수 있을 것이라 생각했다. 그래서 elastic cloud의 공식 문서를 찾아보았다.
공식 문서 - TOP 5 ways to optimize your elastic cloud costs 에서 소개하는 “비용을 최적화할 수 있는 방법”은 아래와 같다.
- 검색 가능한 스냅샷 및 데이터 티어를 사용하여 저장 공간 비용 최적화
- 7.15 릴리즈 이상으로 업그레이드하여 데이터 전송 비용 절감
- 올바른 하드웨어 프로필과 시스템 유형 사용
- 자동 확장 정책 사용
- 클라우드 월 요금 청구로 시작하여 최적의 구성 구축
여기서 2번, 3번, 5번은 이미 충족하고 있었다.
4번도 시도해볼 수 있는 방법이었지만, 이미 용량을 크게 쓰고 있는 현 상태에서 자동 확장 정책을 사용할 필요가 없다고 생각했다. 만약 자동 확장 정책(autoscaling policy)를 적용하려면, 일단 쓰고 있는 저장 공간부터 줄이는 것이 선행되어야 한다.
그래서 1번 방법에 집중해 비용을 줄여보기로 했다. 사실 ‘검색 가능한 스냅샷’도 이미 사용하고 있었고, ‘데이터 티어’도 나름대로 구분하여 데이터를 저장하고 있었다. 하지만, 이 방법들을 정말로 “잘” 사용하고 있었는지 검토가 필요했다.
잘 쓰고 있던거 맞나..?
‘검색 가능한 스냅샷’과 ‘데이터 티어’를 잘 사용하고 있는지 검토하기 위해 Elastic Search에 저장되고 있는 인덱스들을 살펴보았다.
‘A’ 목적으로 사용하는 인덱스(이하 A 인덱스)들은 Index Lifecycle Management(이하 ILM)가 적용되어 있어, 시기에 따라 데이터 티어가 자동으로 변경되고 있었다. 하지만 이 ILM이 인덱스를 사용하는 패턴에 부합하는지 살펴볼 필요가 있었다. 가령 A 인덱스에 적용되고 있던 ILM 정책을 보니, 핫 노드에 머무르는 기간이 일주일 정도로 설정되어 있었다. A 인덱스에 대해 실시간으로 검색이 필요한 경우는 하루-이틀이 대부분이었다. 이틀이 지난 데이터를 실시간으로 검색해야 하는 일은 거의 없기 때문에, 일주일이나 핫 노드에 머무르는 건 비효율적일지도 모른다는 생각이 들었다.
‘B’ 목적으로 사용하는 인덱스(이하 B 인덱스)들은 쌓이기만 하고 있었다. ILM이 적용되어 있지 않아 항상 핫 노드에만 쌓이고 있었다. 과거 데이터를 확인해야 하는 경우도 있어 과거 인덱스를 삭제하지 않는 상태였다. 따라서 시간이 지날수록 핫 노드 용량 사용률은 선형적으로 증가하게 된다.
잘 쓰기 위해서..
A 인덱스와 B 인덱스 각각에 대한 문제를 정리하면, 다음과 같다.
- A 인덱스의 사용 패턴에 맞게 ILM 정책이 정의되어 있지 않다.
- B 인덱스는 ILM 정책이 적용되어 있지 않아 hot node에만 쌓이고 있다.
위 문제들을 해결하기 위해 다음과 같은 순서로 접근해보기로 했다.
- A/B 인덱스의 사용 패턴에 맞게 ILM 정책을 새로 정의한다.
- 이미 적재된 B 인덱스에 ILM 정책을 적용하여 올바른 티어로 이동시킨다.
- 새로 쌓이는 B 인덱스에 자동으로 ILM 정책이 적용되도록 한다.
1. ILM 정책 새로 정의하기
각 인덱스의 사용 패턴에 맞게 ILM 정책을 새롭게 정의할 필요가 있었다. 그 전에, ILM 정책에서 어떻게 데이터 티어를 나누어 사용할 것인지에 대해 고민해보았다.
사전 지식: Elastic Search의 데이터 노드 구성
Elastic Search 클러스터는 여러 노드로 구성된다. 노드는 데이터를 저장하거나 인덱싱과 검색을 지원하는 인스턴스이다. 노드는 그 역할에 따라 마스터 노드, 데이터 노드, 인제스트 노드로 분류할 수 있다.
그 중 데이터 노드는 인덱싱한 데이터를 저장하는 역할을 수행한다. 뿐만 아니라 인덱싱된 데이터를 검색하거나 집계하는 등 데이터를 처리하는 일들을 담당한다. 데이터 노드는 저장하는 데이터의 성격에 따라 핫/웜/콜드 노드로 구분할 수 있고, 같은 구분에 속하는 노드들의 집합을 ‘데이터 티어’라고 한다. 데이터 티어마다 노드가 저장하는 데이터의 성격에 맞게 서로 다른 사양으로 운영하여 전체 클러스터 효율을 높일 수 있다. 자주 사용하는 노드에 더 좋은 리소스를 할당하고, 자주 사용하지 않는 노드에는 보다 저렴한 리소스를 할당하는 방식이다.
데이터 티어를 효율적으로 운영하는 방법은 다음과 같다. (출처: 엘라스틱 서치 개발부터 운영까지 502pg)
- 핫 노드에는 충분한 리소스와 하드웨어를 할당하여, 인덱싱과 검색이 빈번히 일어나는 인덱스를 저장한다.
- 웜 노드에는 핫 노드만큼 좋은 디스크나 큰 메모리는 필요하지 않지만 많은 데이터를 저장하기 위한 대용량 디스크를 사용한다. 쿼리의 빈도가 낮고 인덱싱은 일어나지 않는 인덱스를 웜 노드에 저장한다.
- 콜드 노드는 최소한의 사양으로 디스크의 용량만 필요한 만큼 갖추면 된다. 주로 검색을 수행하지는 않지만 데이터 보존 기간 정책상 보관해야만 하는 데이터를 저장한다. 콜드 노드에서는 인덱스를 메모리에 띄워놓지 않고 검색 요청이 올 때 인덱스 파일을 열어 탐색하기 때문에 검색 시간이 핫/웜에 비해 많이 소요된다.
사내 ELK 데이터 노드 운영 전략 세우기
위 내용을 참고하여, 어떻게 데이터 티어를 나누어 사내 ELK 데이터 노드를 운영할지 고민해보았다. 이에 더하여 어떤 데이터를 어떤 티어에 저장할지에 대한 기준도 아래와 같이 정했다.
a) 핫 노드
- 인덱싱이 수행되어야 하는 인덱스를 저장한다.
- 실시간성 검색이 필요한 인덱스를 저장한다.
- A 인덱스와 B 인덱스 모두 로그성 데이터이다. 사내에서 로그성 데이터는 하루-이틀 내에만 활발히 검색되고 이후로는 검색빈도가 낮아진다. 따라서 생성된지 하루-이틀 내의 데이터만 핫 노드에 저장한다.
- 핫 노드에 가장 좋은 리소스를 할당하기 때문에 가격이 가장 비싸다. 핫 노드에 저장하는 데이터를 최소화하여 운영할 수 있는 범위 내에서 최소한의 사양으로 선택한다.
b) 웜 노드
- 빈번히 검색되지만 실시간성 검색이 필요하지 않은 인덱스를 저장한다.
- 사내에서 로그성 데이터는 4-5일이 넘어가면 검색 빈도가 급격히 줄어든다. 따라서 생성된지 4-5일이 지난 데이터를 웜 노드에 저장한다.
- 핫 노드에 위치시키기엔 비용이 비싸고, 프로즌 노드에 저장하기에는 검색이 종종 일어나는 데이터를 웜 노드에 저장한다.
c) 콜드 노드
- 운영하지 않는다.
d) 프로즌 노드
- 검색이 거의 일어나지 않는 데이터를 저장한다. 업데이트가 일어나지 않는 데이터를 저장하기 때문에 ‘searchable snapshots’을 사용하여 데이터를 저장한다.
- 4-5일이 넘어간 로그성 데이터를 프로즌 노드에 저장한다.
- 보관해야 하는 데이터 용량에 맞게 디스크 사양을 선택한다. 사내에서 관리하는 인덱스는 위 기준에 따라 대부분이 프로즌 노드에 저장되어야 하므로 큰 용량을 갖추도록 한다.
ILM 정책 정의하기
이렇게 정한 데이터 노드 운영 전략에 따라, A 인덱스와 B 인덱스에 적용할 ILM 정책을 정의해보았다.
위에서 언급했듯이, A 인덱스에 적용되어 있던 기존 ILM 정책을 살펴보니 핫 노드에 머무르는 기간이 일주일로 설정되어 있었다. A 인덱스는 로그성 데이터이고, 실시간으로 검색하는 경우는 이틀 이내의 데이터 뿐이므로 핫 노드에 머무르는 기간을 이틀로 변경했다. B 인덱스도 마찬가지의 이유로 핫 노드에 머무르는 기간을 하루로 설정했다.
웜 노드로 이동할 때에는 ‘Shrink’ 옵션을 사용했다. 기존 A 인덱스에 적용된 ILM 정책에서 핫 노드에 머무르는 경우 샤드 수를 2개로 설정했었다.
샤드 하나하나마다 시스템 리소스를 차지하는데, 자주 검색되지 않는 인덱스에도 샤드를 두 개 할당하는 것은 비효율적이라고 판단했다.
핫 노드에서 샤드를 두 개로 설정한 것은 성능과 처리량을 높이기 위함이었는데, 웜 노드에서는 이 정도의 성능이 필요하지 않다고 생각했다.
따라서 ‘Shrink’ 옵션을 사용하여 샤드 수를 1개로 줄였다. B 인덱스에도 동일하게 적용했다.
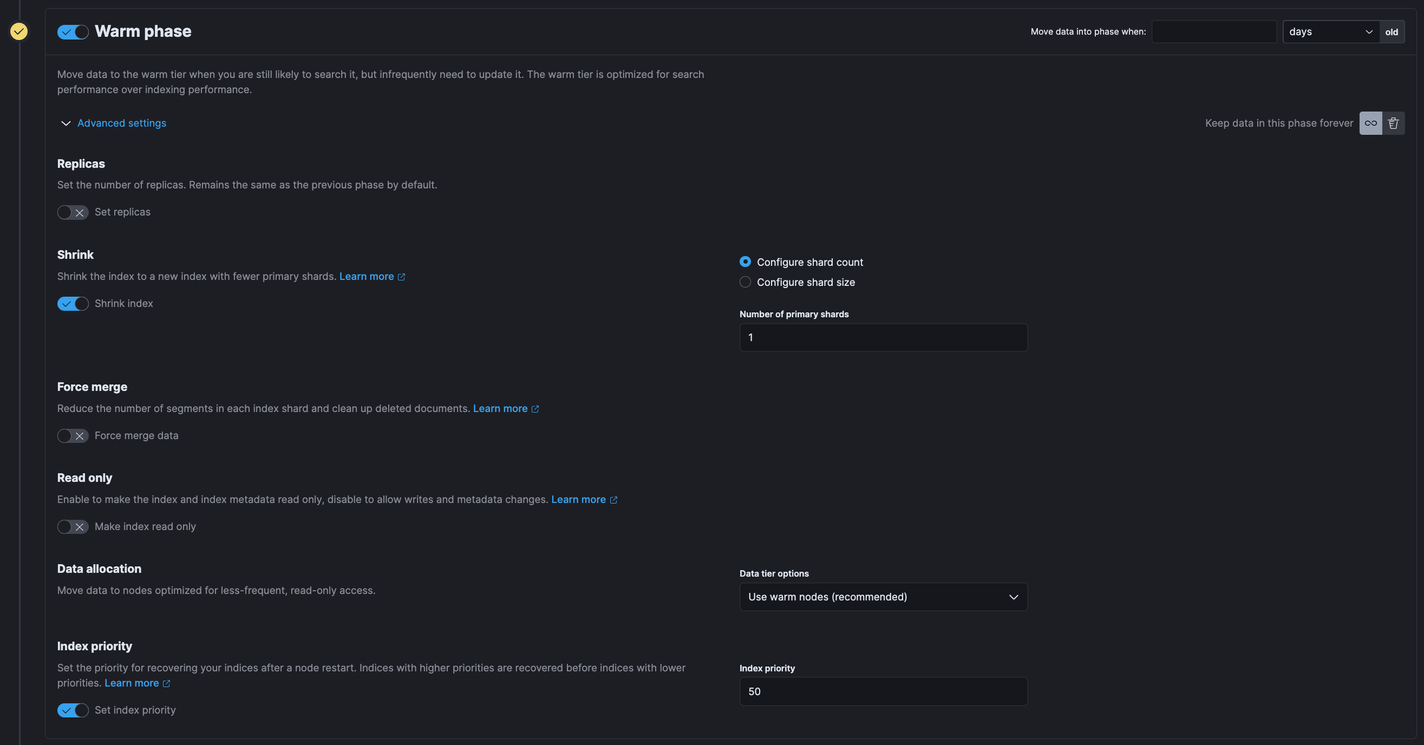
프로즌 노드로 이동할 때, 웜 노드에서 얼만큼 머무른 이후 프로즌 노드로 옮길 것인지 설정하는 부분이 있다.
A 인덱스의 경우 5일이 지난 데이터를 프로즌 노드로 이동하도록 했다. ‘Searchable Snapshot’ 설정은 기본값을 사용했다.
마찬가지로 B 인덱스에도 동일하게 적용했다.

A 인덱스 ILM 정책 수정하기
A 인덱스에는 이미 ILM 정책이 적용되어 있었다. 기존 정책을 수정하는 것으로 새롭게 정의한 ILM 정책을 적용할 수 있었다. 각 A 인덱스는 변경된 ILM 정책에 따라 올바른 티어로 이동했다. 3-7일 정도가 지난 인덱스가 핫 노드에서 웜 노드로 이동하는 것을 확인할 수 있었다.
2. 과거 인덱스에 ILM 정책 적용하기
B 인덱스에는 ILM 정책이 적용되어 있지 않았다. 별도의 ILM 정책이 지정되어 있지 않은 인덱스의 경우, 핫 노드에서 데이터가 인덱싱된 이후로도 계속 핫 노드에 머무르게 된다. 이미 생성된 B 인덱스가 핫 노드에만 쌓이고 있었기 때문에, 새롭게 정의한 ILM 정책을 적용하여 올바른 티어로 이동시켜야 했다.
Stack Management > Index Management 로 이동하여 ILM 정책을 적용할 B 인덱스를 선택했다.
Manage > Add lifcecycle policy 를 선택하여 ILM 정책을 적용했다.
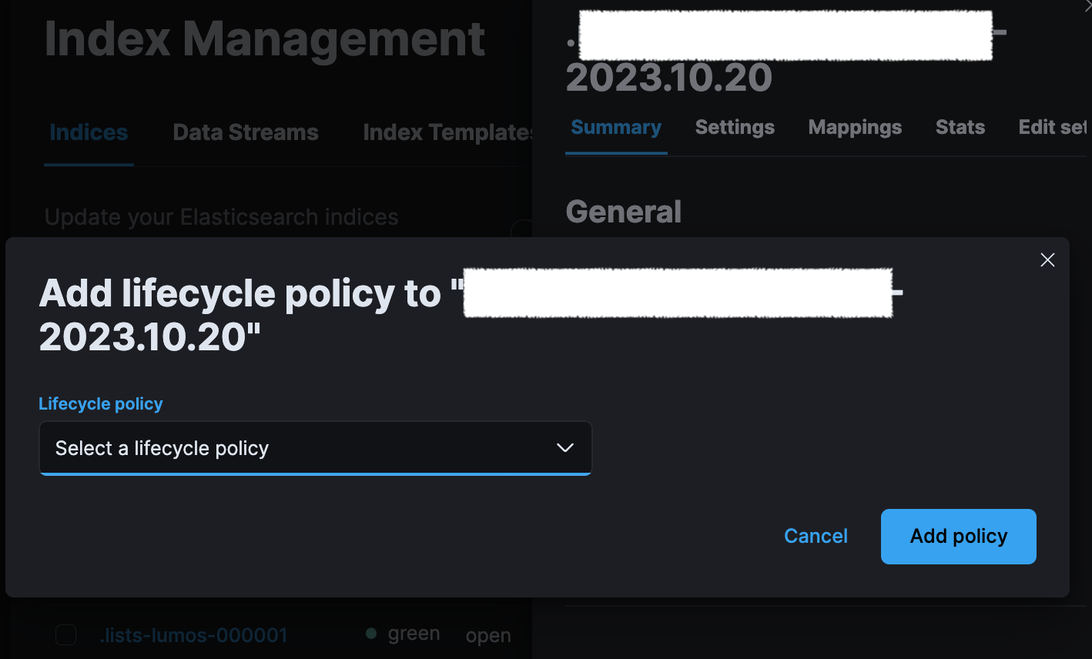
ILM을 적용하면, 정책 세부 내용에 따라 각 인덱스가 적절한 노드로 이동하는 것을 아래 사진과 같이 확인할 수 있었다.

과거 B 인덱스가 수십개 있었기 때문에, 일일이 인덱스를 선택하여 ILM 정책을 적용하는 것은 비효율적이었다.
B 인덱스는 일자별로 생성되어 인덱스 이름이 prefix-날짜 형식이었다. 일정한 규칙이 있어 아래와 같은 API를 통해 여러 인덱스에 ILM 정책을 한번에 적용할 수 있었다.
(Dev Tools > Console 에서 실행)
PUT {인덱스 이름 prefix}-*/_settings
{
"index": {
"lifecycle": {
"name": {lifecycle policy 이름}
}
}
}
3. 새롭게 저장되는 인덱스에 자동으로 ILM 정책 적용하기
인덱스가 생성될 때마다 2번 방법으로 인덱스가 적절한 시기에 적절한 노드로 이동하도록 설정할 수도 있다.
하지만 지속적인 관리를 위해서는 자동화가 필요하다. Index Template을 사용하면 인덱스가 새로 생성될 떄마다
적합한 ILM 정책이 자동으로 적용되도록 설정할 수 있다.
A 인덱스는 Index Template가 이미 설정되어 있어 새로 생성되는 A 인덱스에 자동으로 ILM 정책이 적용되고 있었다.
하지만 B 인덱스는 그렇지 앟았다. 새롭게 저장되는 B 인덱스가 자동으로 ILM 정책이 적용되도록 설정할 필요가 있었다.
Index Template에 ILM 정책을 연결해두면, Index Template 을 적용받는 인덱스들은 자동으로 ILM 정책이 적용된다.
먼저, Index Template을 적용할 인덱스 이름의 규칙을 기입하여 아래와 같이 Index Template을 생성했다.
만약 trip으로 시작하는 인덱스에 템플릿을 적용하고 싶다면 “Index patterns”에 trip-*를 입력하면 된다.
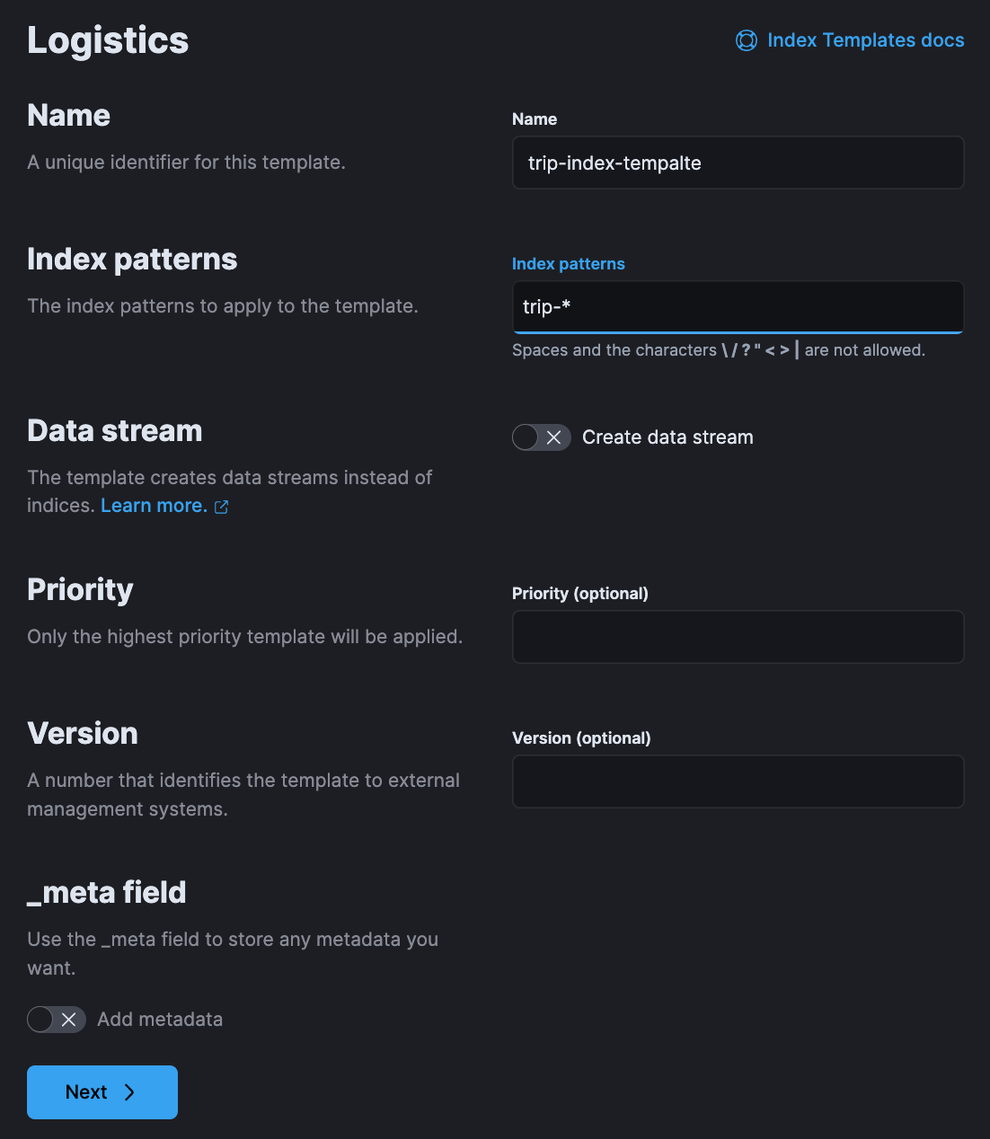
Index Template 를 생성할 때, Index Settings 단계에서 ILM 정책을 연결할 수 있었다.
{
"index": {
"lifecycle": {
"name": "something-index-lifecycle-policy"
},
"refresh_interval": "10s"
}
}
위 설정에서, refresh_interval은 얼만큼의 주기로 각 인덱스를 확인할 것인지에 대한 값이다.
설정한 주기마다 인덱스를 확인하여 ILM 정책에 맞게 특정 티어로 이동할지 여부를 판단한다.
ILM 정책을 모두 적용했더니..
위에서 정의한 ILM 정책을 모두 적용하고 나니, A 인덱스와 B 인덱스 모두 핫 노드에 오래 머무르지 않게 되었다. 그 결과로 핫 노드 용량 사용률이 30% 정도로 줄어들었다. 용량을 늘리기 전에 사용하고 있었던 용량보다도 더 줄일 수 있을 정도였다.
사용하고 있는 용량의 50% 의 사양을 선택하려 했으나 25%의 사양으로도 충분할 것 같았다. 그래서 핫 노드의 용량을 기존의 25%로 선택하여 핫 노드 운영 비용을 극적으로 줄일 수 있었다.
대신 ‘프로즌 노드’로 이동하는 데이터가 많아졌기 때문에 프로즌 노드의 용량을 더 늘려야 했다. 프로즌 노드의 용량을 늘리는 것은 핫 노드의 용량을 늘리는 것보다 비용이 저렴하기 때문에, 비용을 줄이는 데에는 큰 영향을 미치지 않았다.
결론적으로는 매달 Elastic Cloud를 운영하는 데 지출하는 비용을 절반으로 줄이게 되었다.
마치며
속시원했다. 몇개월간 미뤄둔 일을 해냈다는 것만으로도 몸과 마음이 홀가분해지는 기분..!
비용을 줄이기 위해서 이 작업을 시작했지만, 이를 통해서 사내 Elastic Cloud 노드 운영 정책을 검토하고 개선할 수 있었던 것도 큰 수확이었다. 특히 ILM 정책을 적용하는 과정에서, 어떻게 데이터 티어를 나눌지에 대한 공통된 기준을 정할 수 있었다.
이 기준에 대한 문서와 ILM 정책을 적용하는 방법 문서를 작성하여 사내에 공유하기도 했다.
다른 팀에서도 비용과 클러스터 안정성을 유지한 채로 Elastic Cloud를 사용하기를 바라며.. B 인덱스를 처음 저장할 때처럼 데이터를 핫 노드에만 쌓는 실수가 반복되지 않기를 바라며..!
이번에는 ILM 정책을 적용하는 방식으로 비용을 줄였으나, 여전히 운영 측면에서 아직 부족한 점이 많아 보인다. 앞서 설명했듯이, 핫 노드가 마스터 노드와 데이터 노드를 겸하고 있어, 데이터 용량 관리가 클러스터 전체 안정성에 영향을 미치게 된다. 여러 책과 문서에서 권장하듯, 마스터 노드와 데이터 노드를 분리하여 각 노드가 수행하는 역할에 알맞게 리소스를 할당하면 더욱 효율적으로 운영할 수 있을 것이다. 또한, 공식 문서에서 제안한 방법 중 하나인 ‘자동 확장 정책’을 적용해볼 수도 있을 것이다. 노드를 조금 더 타이트하게 운영하면서 필요에 따라 확장할 수 있게끔 하면 비용을 더욱 줄이면서 클러스터 안정성을 유지할 수 있을 거라 기대한다.
비록 이번에 위 작업들을 함께 진행하지는 못했지만, 틈틈히 개선해가면서 더욱 효율적으로 운영해보고 싶다 💪
Leave a comment